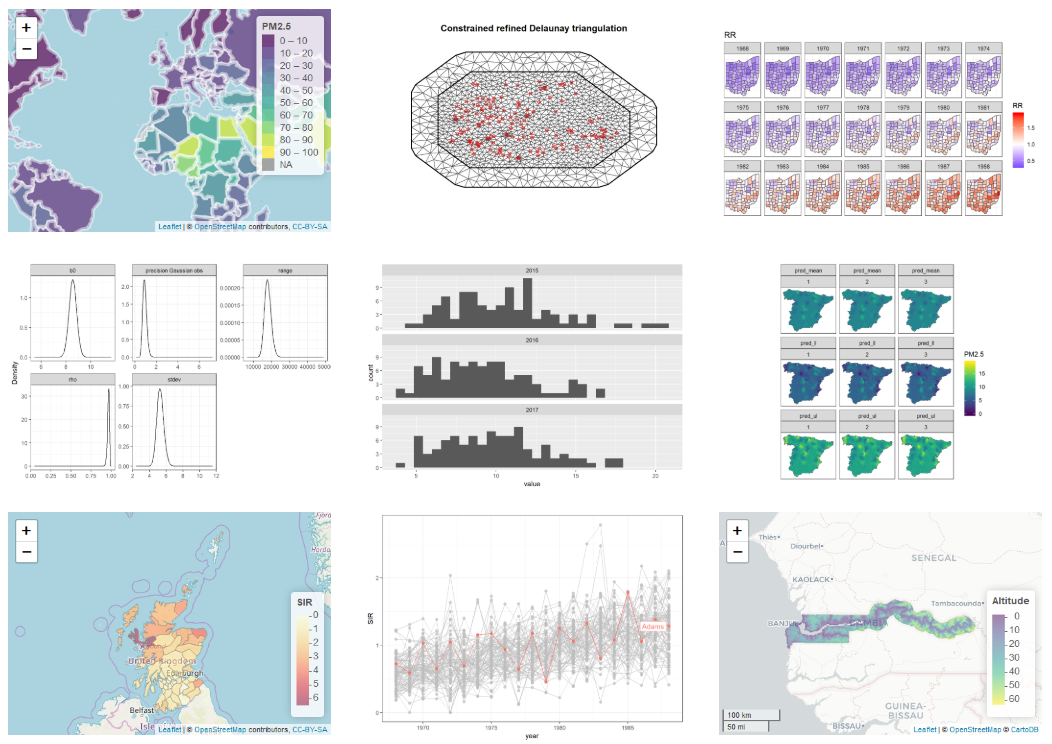
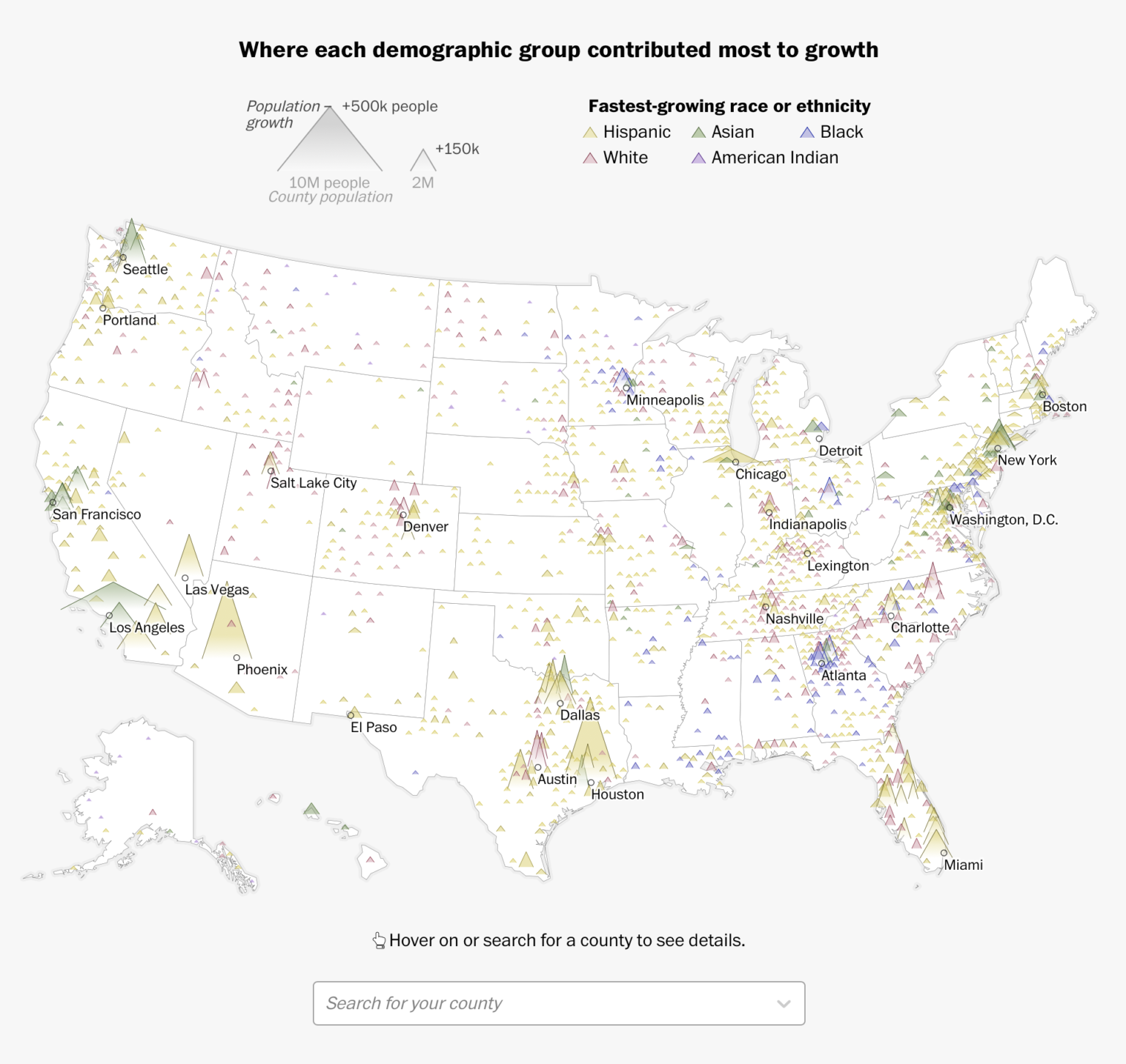
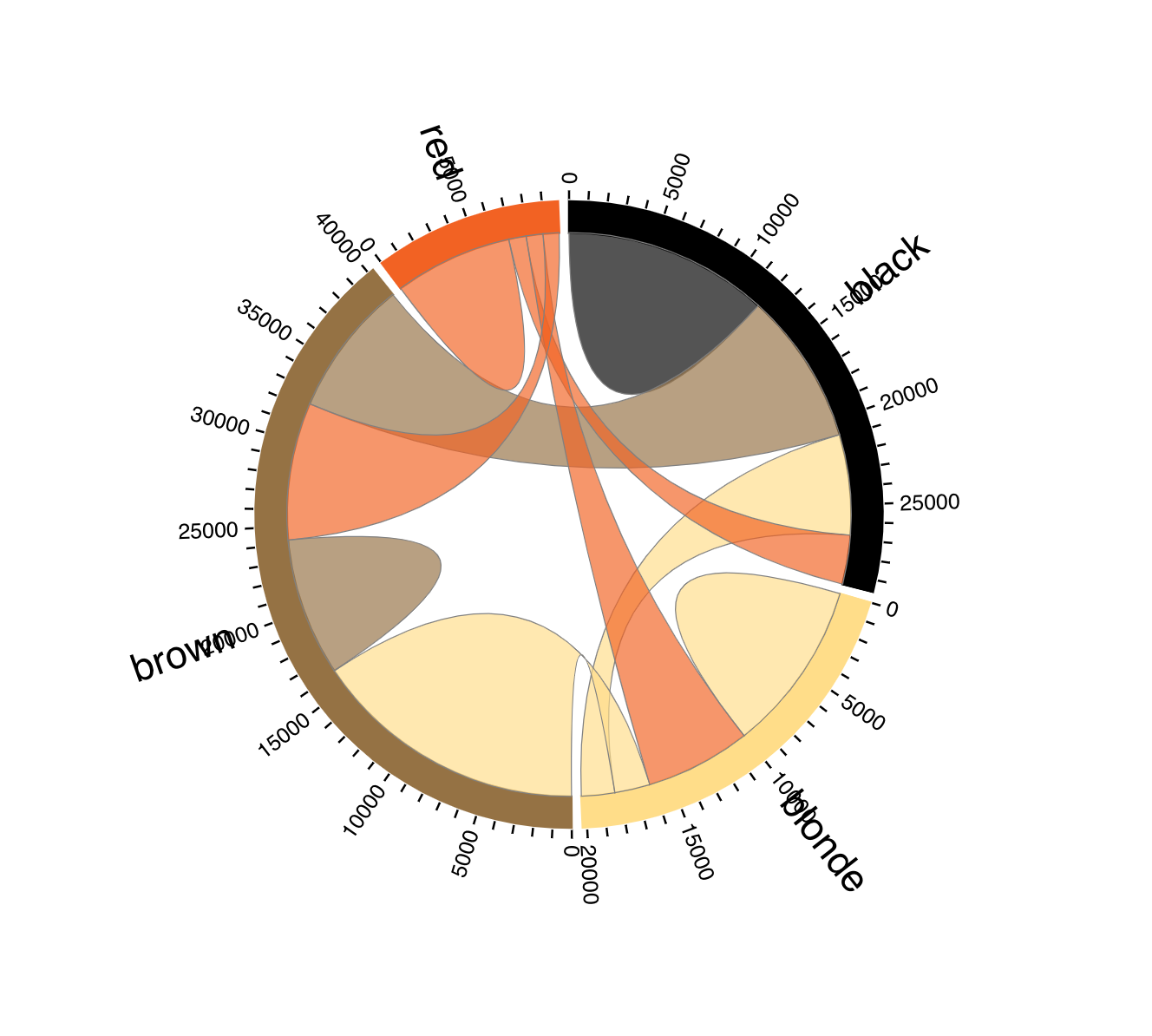
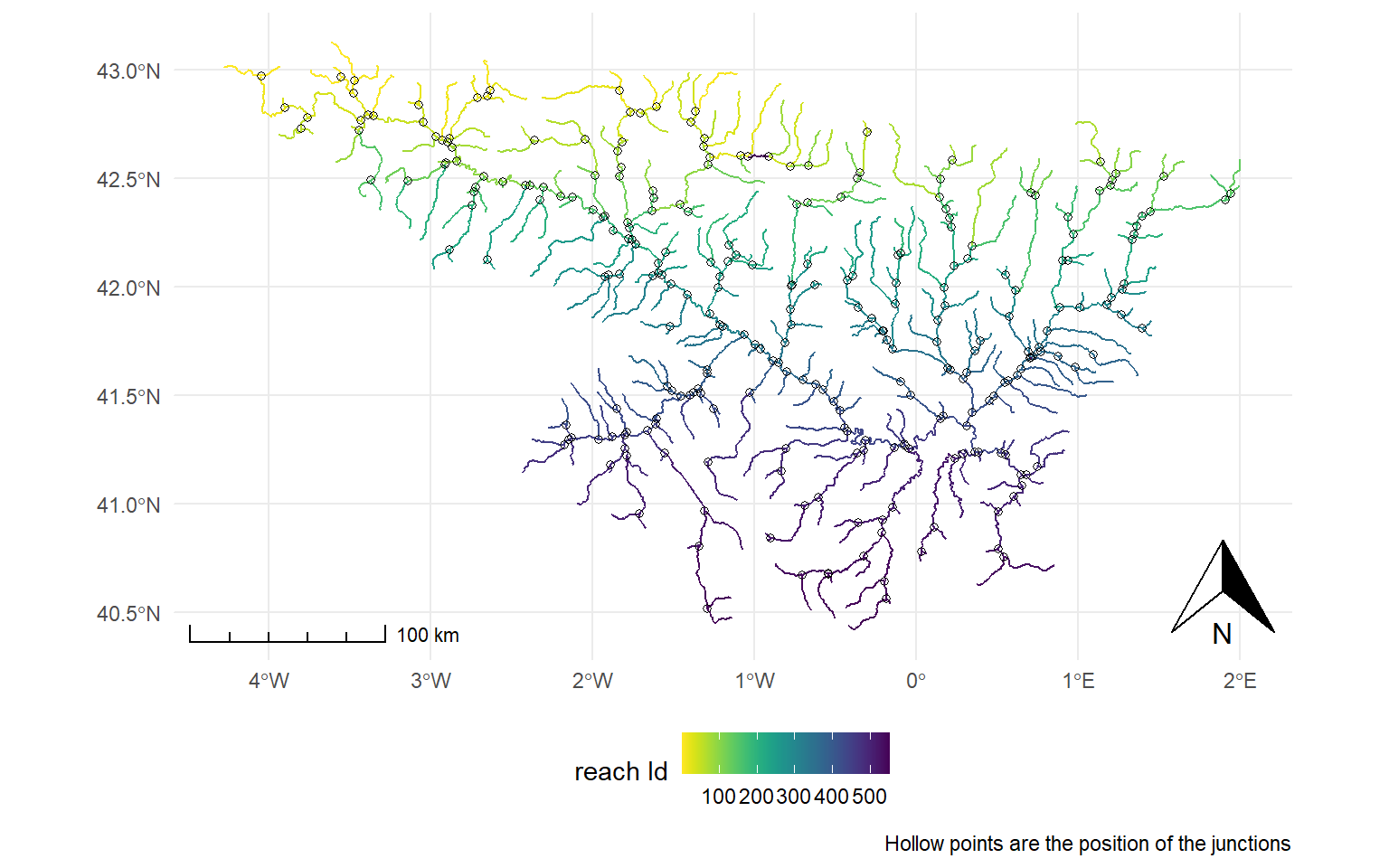
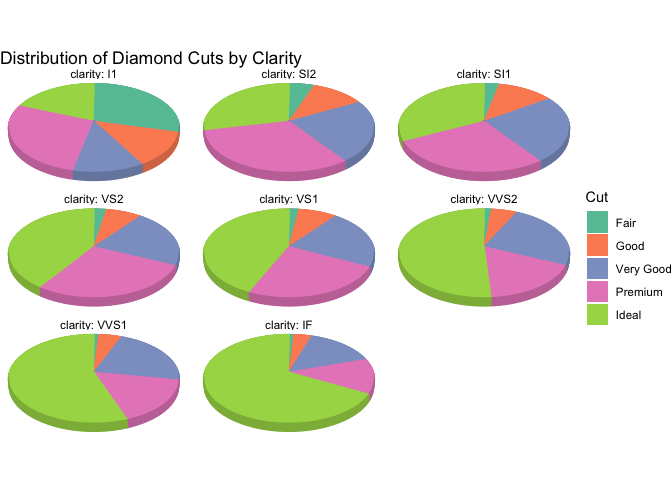
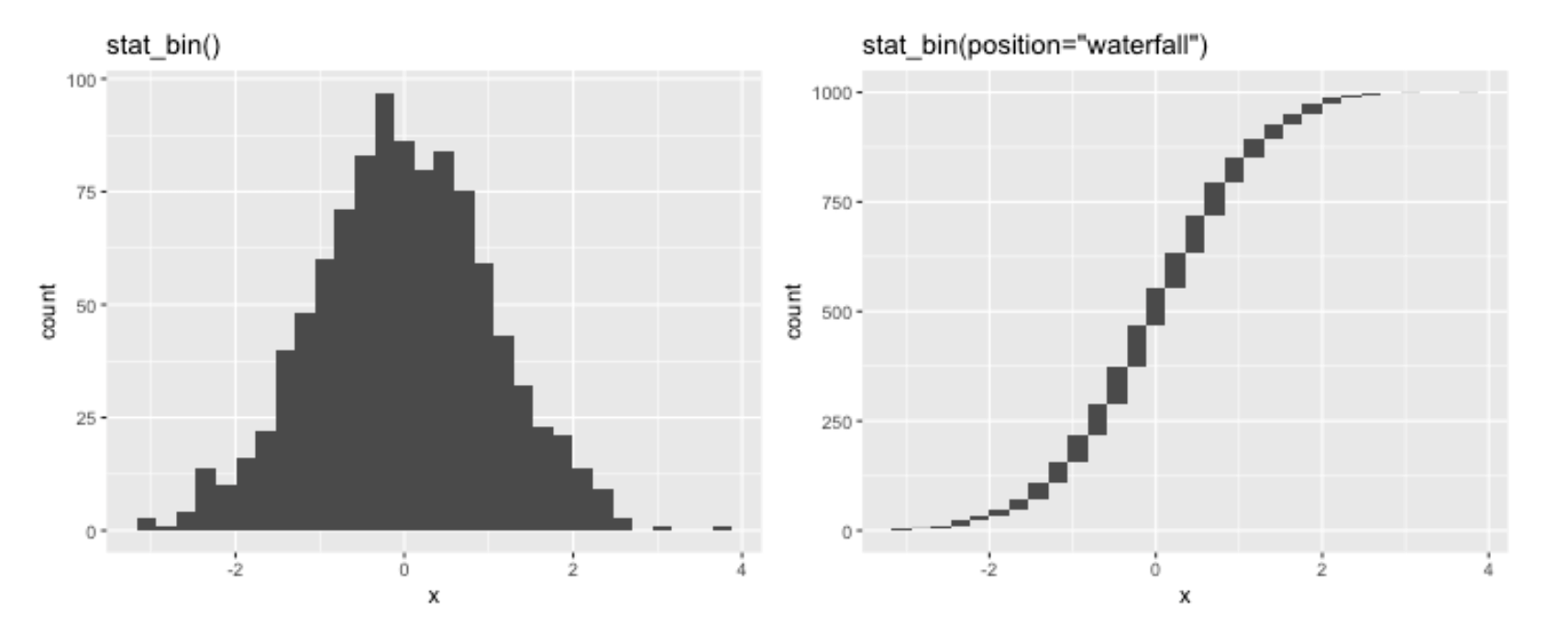
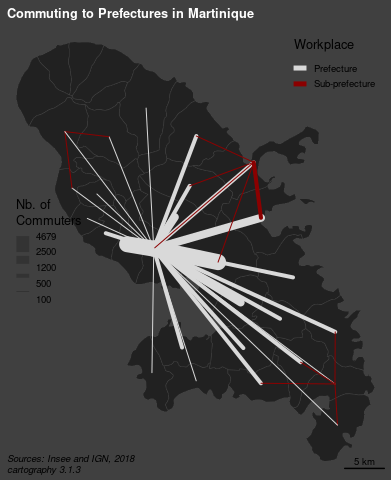
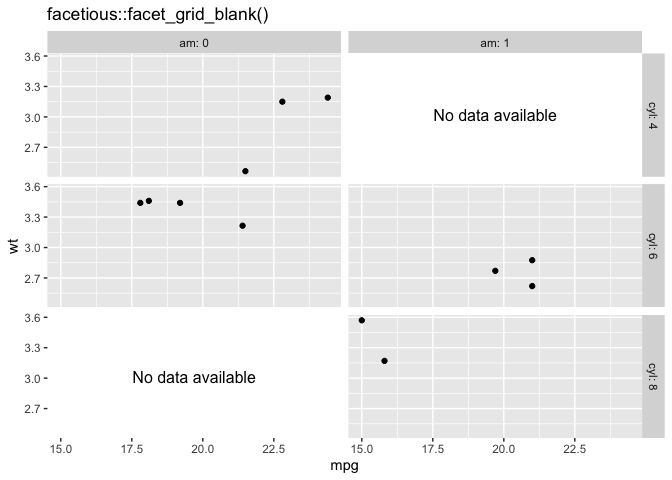
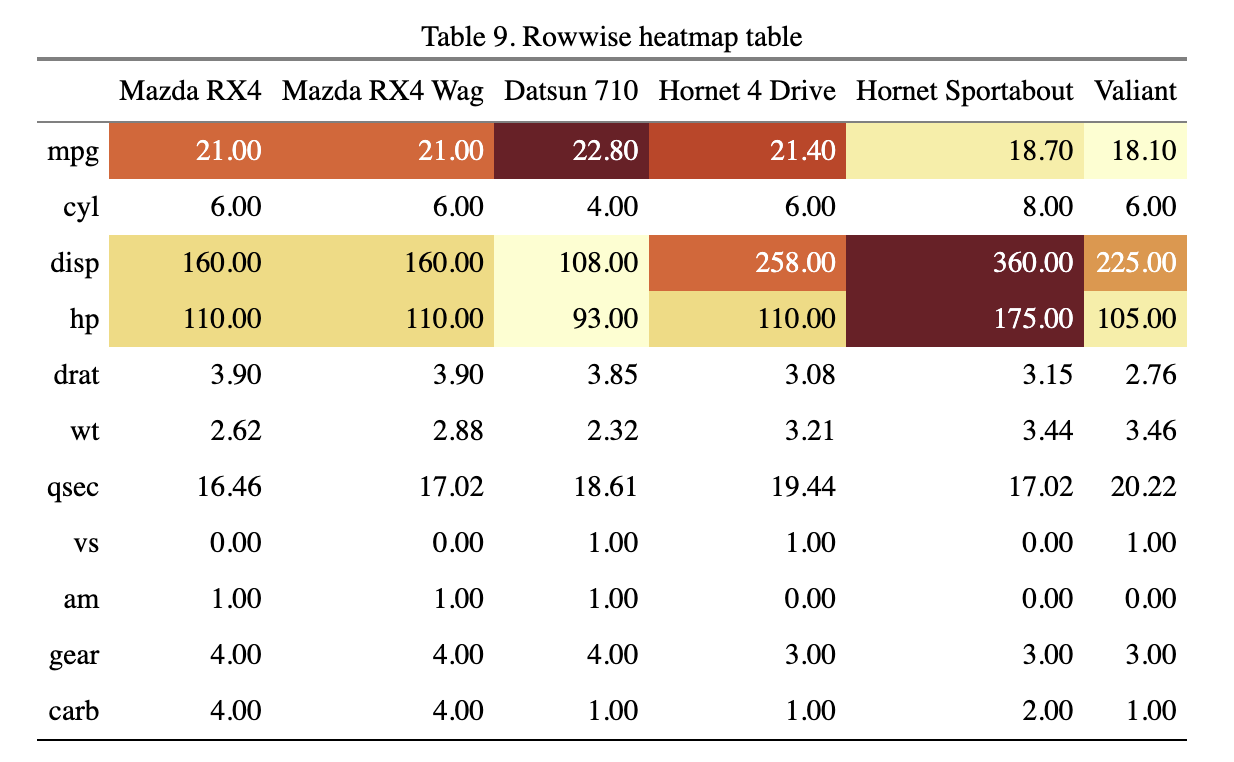
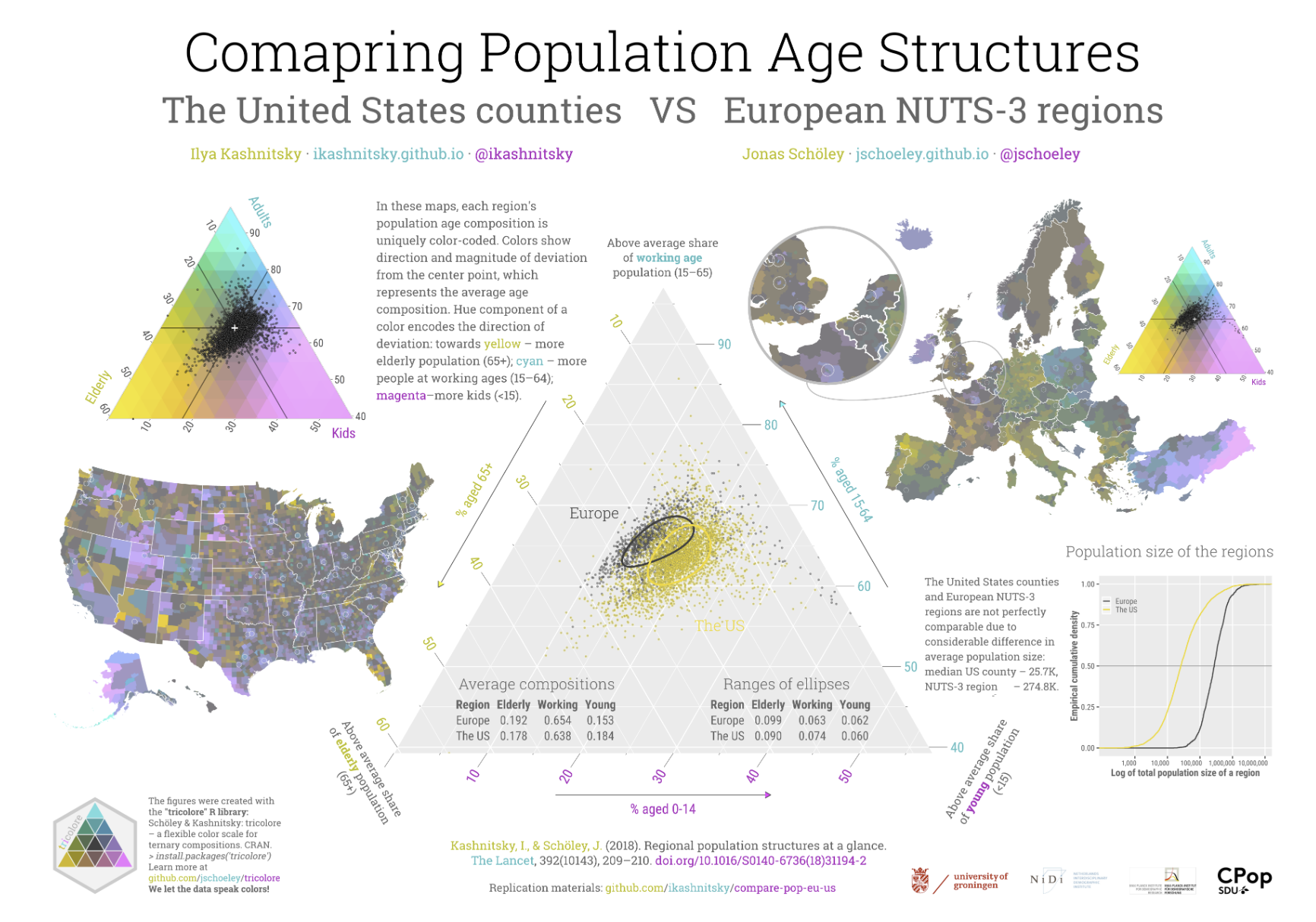
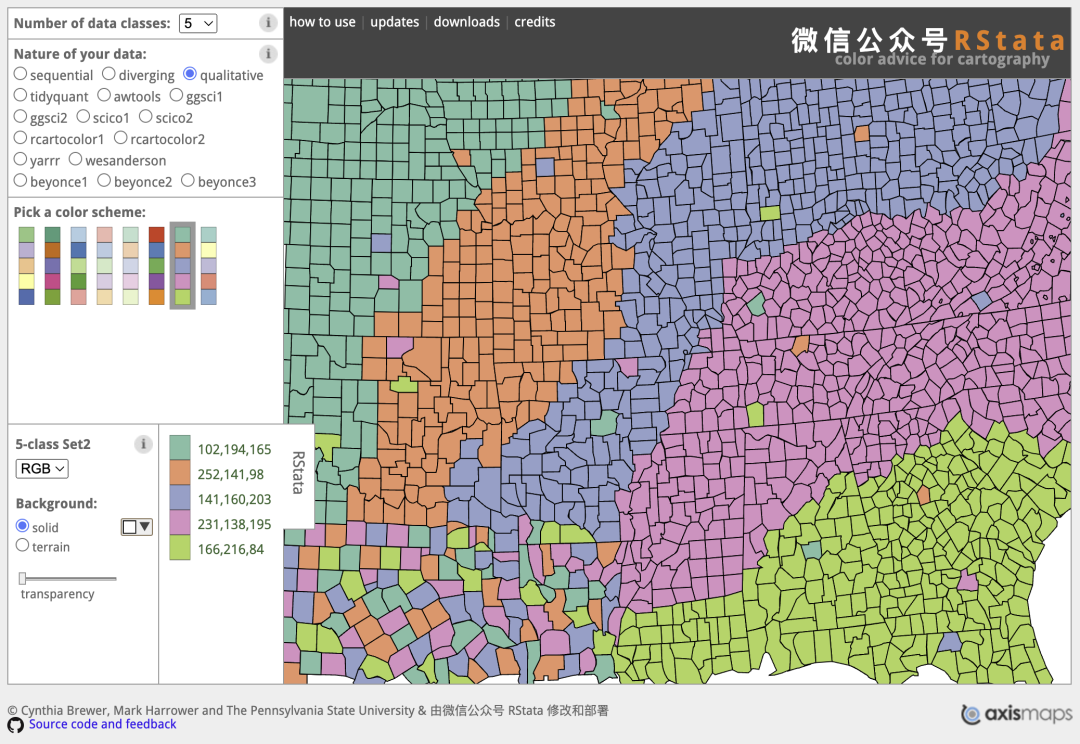
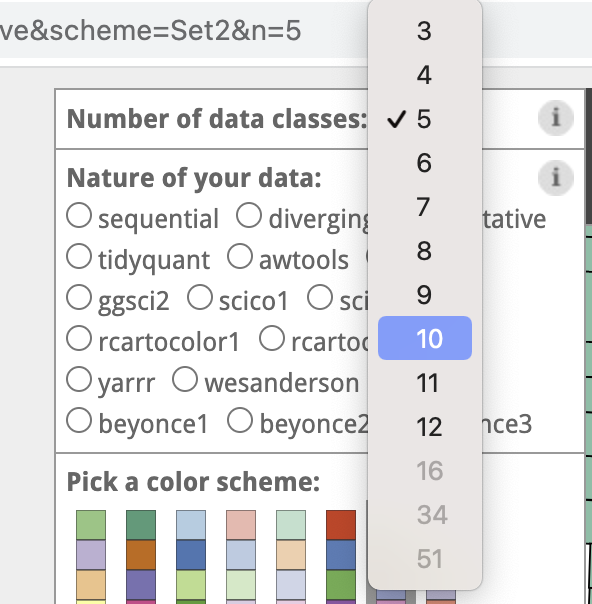
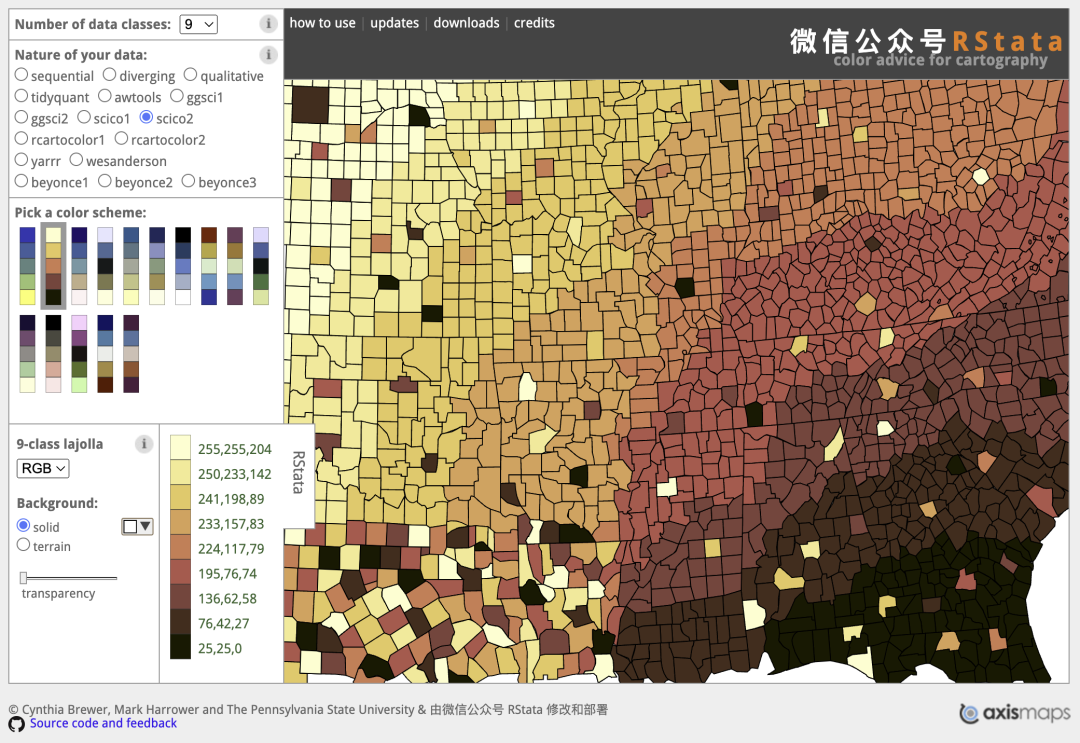
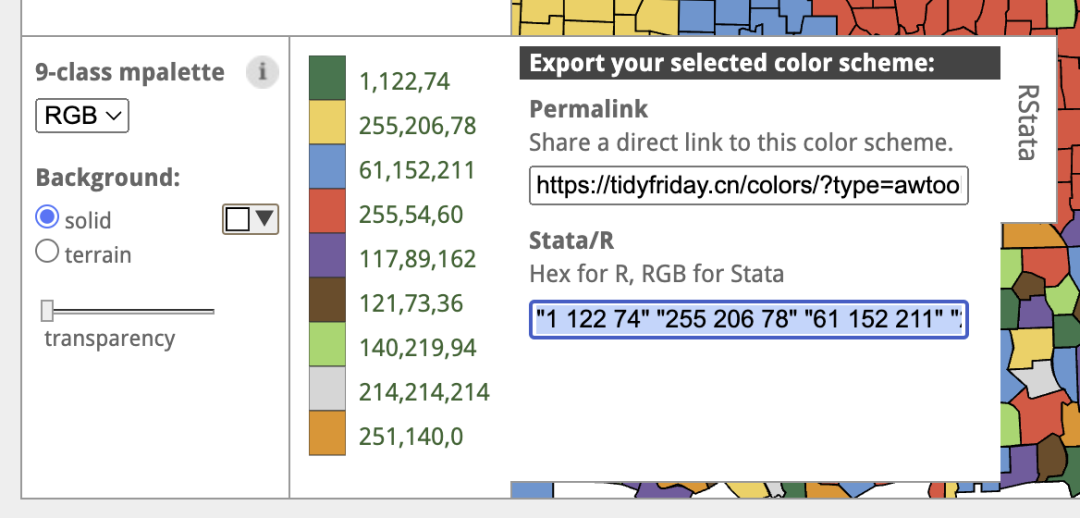
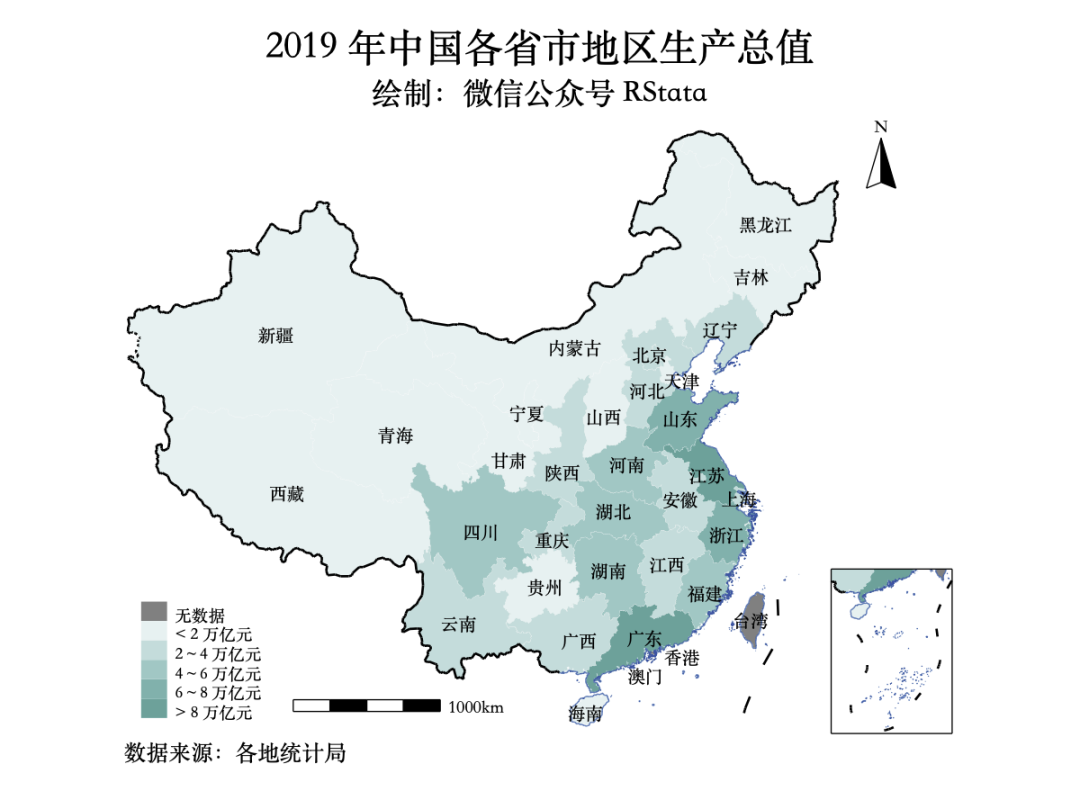
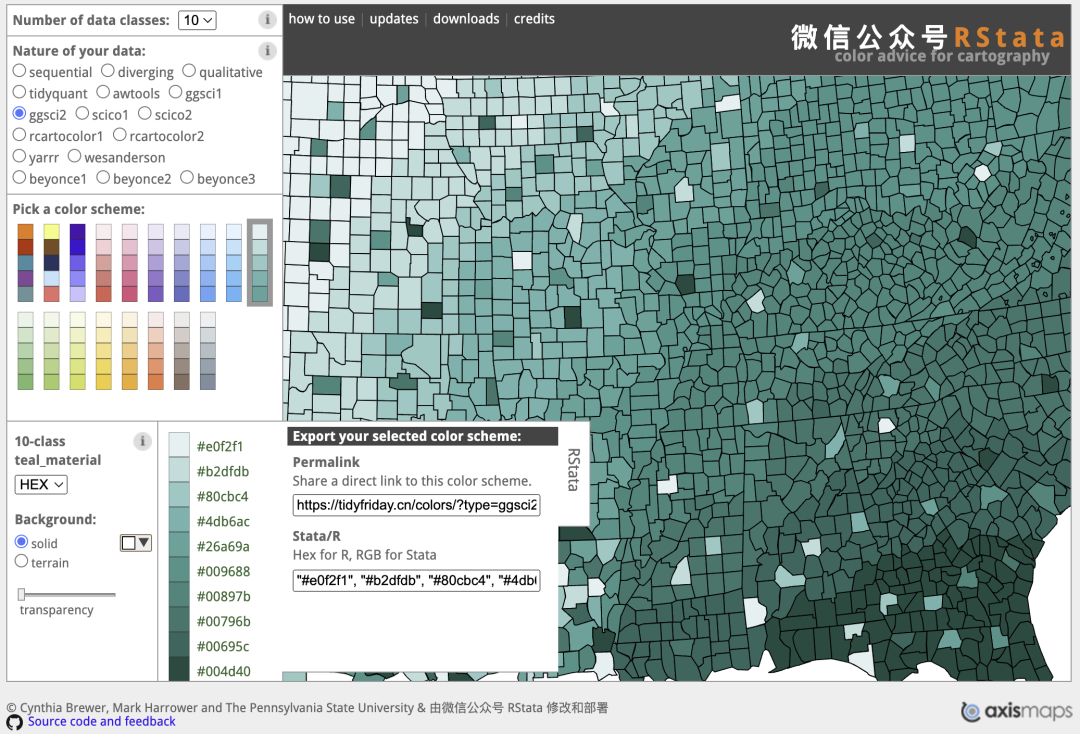
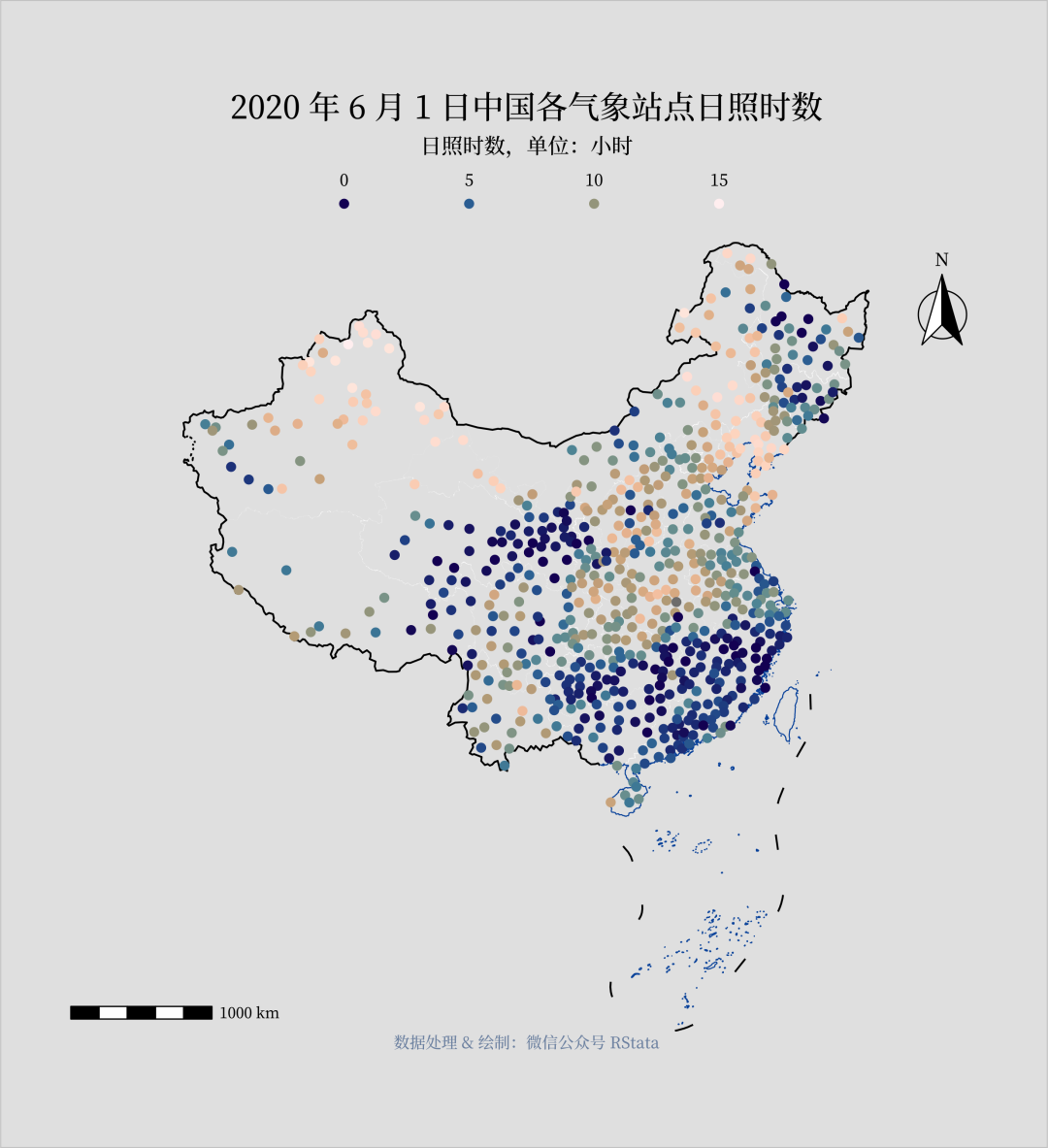
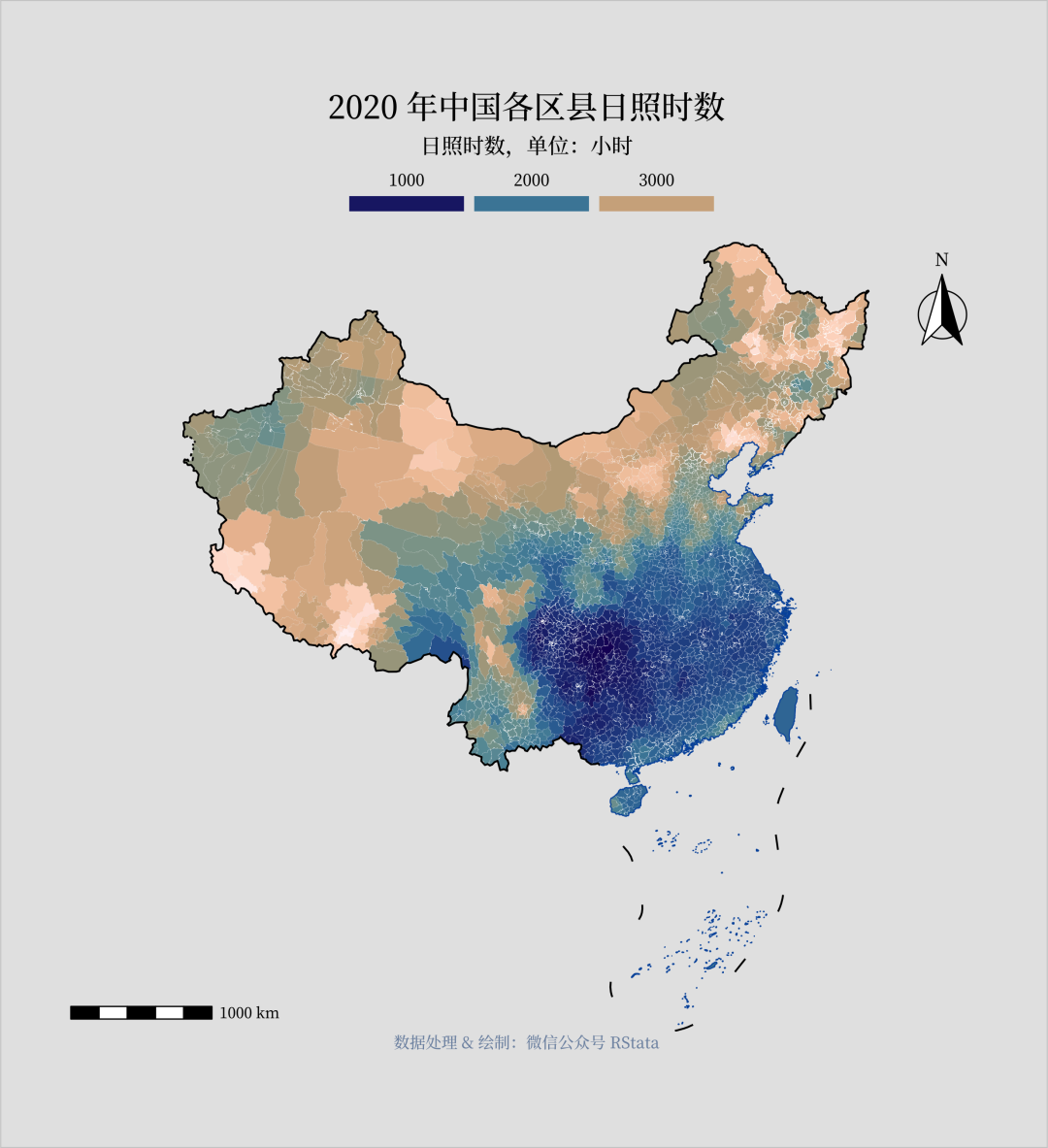
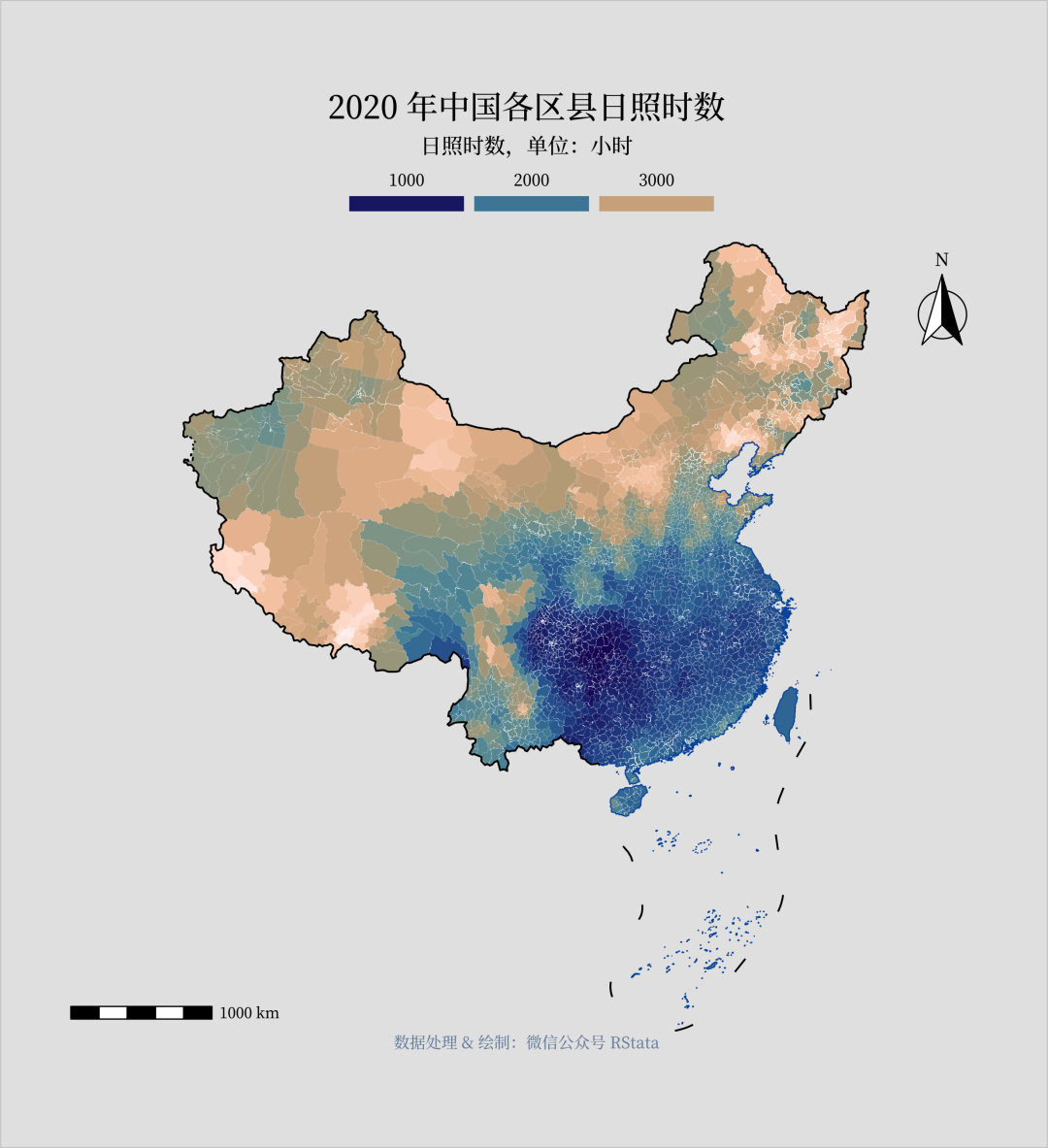
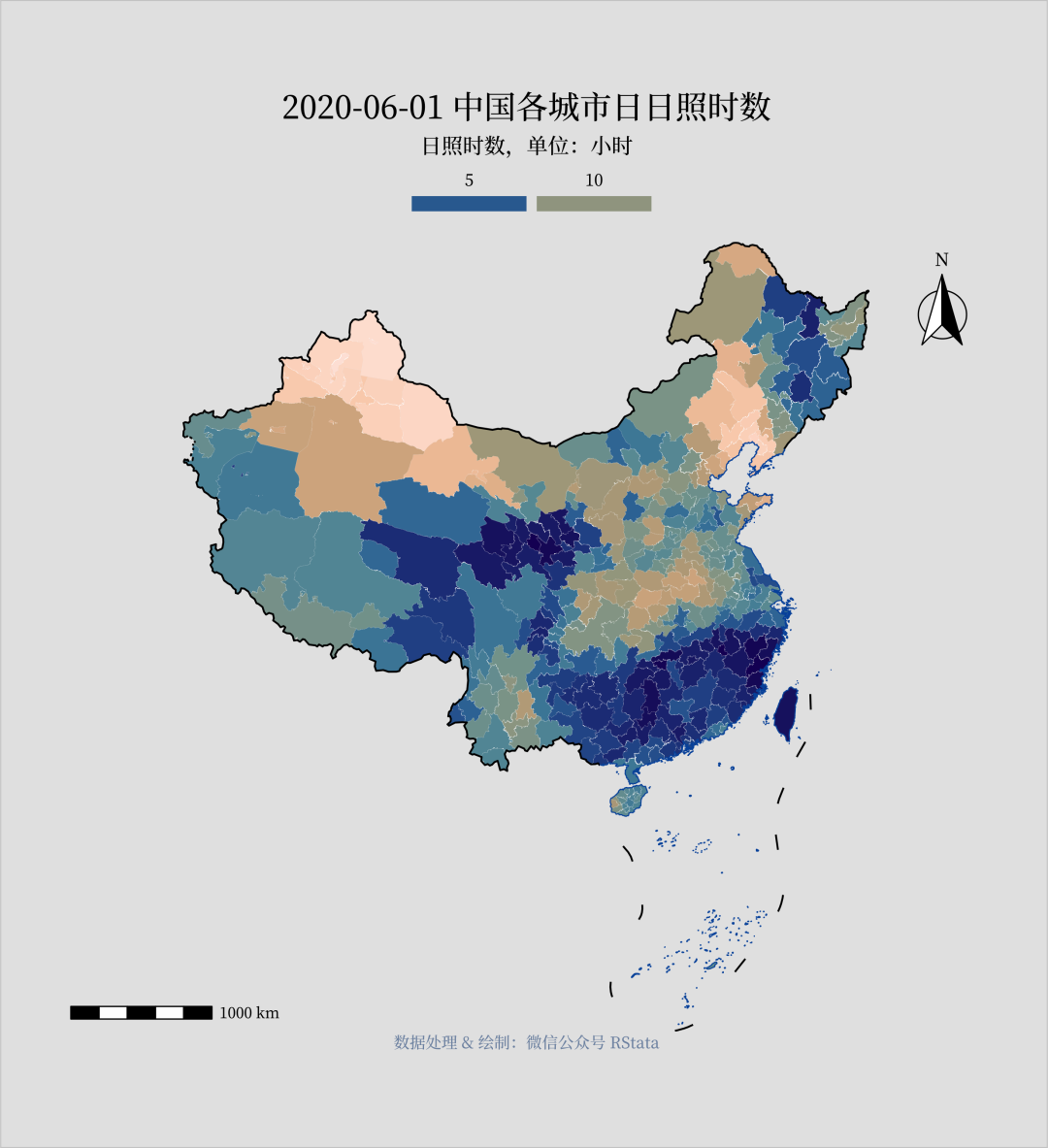
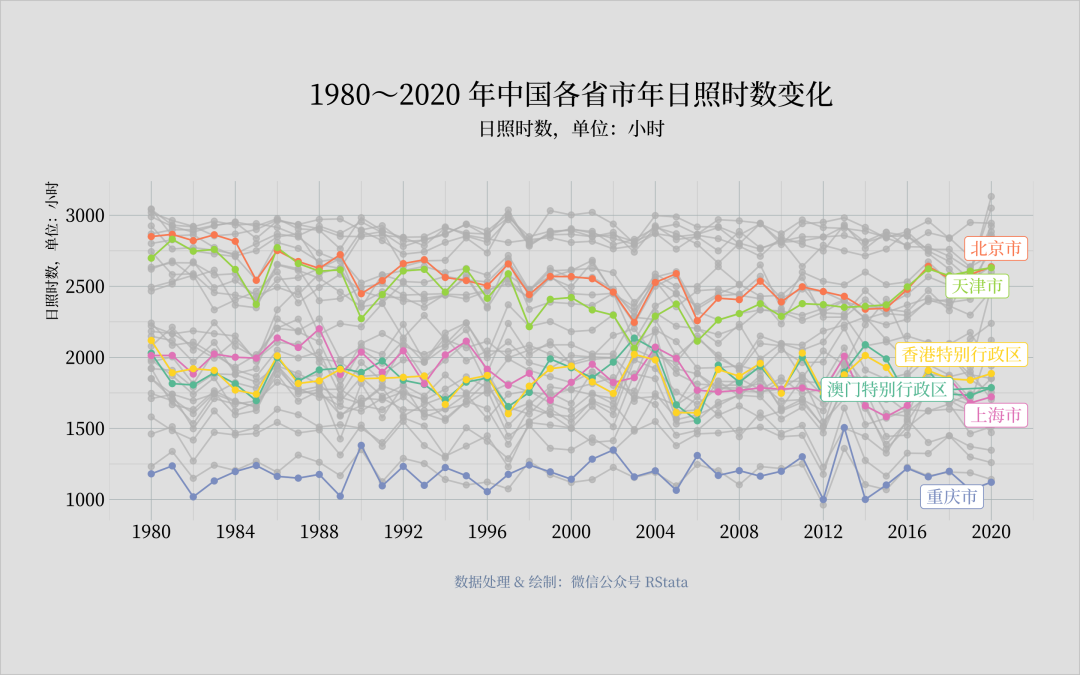
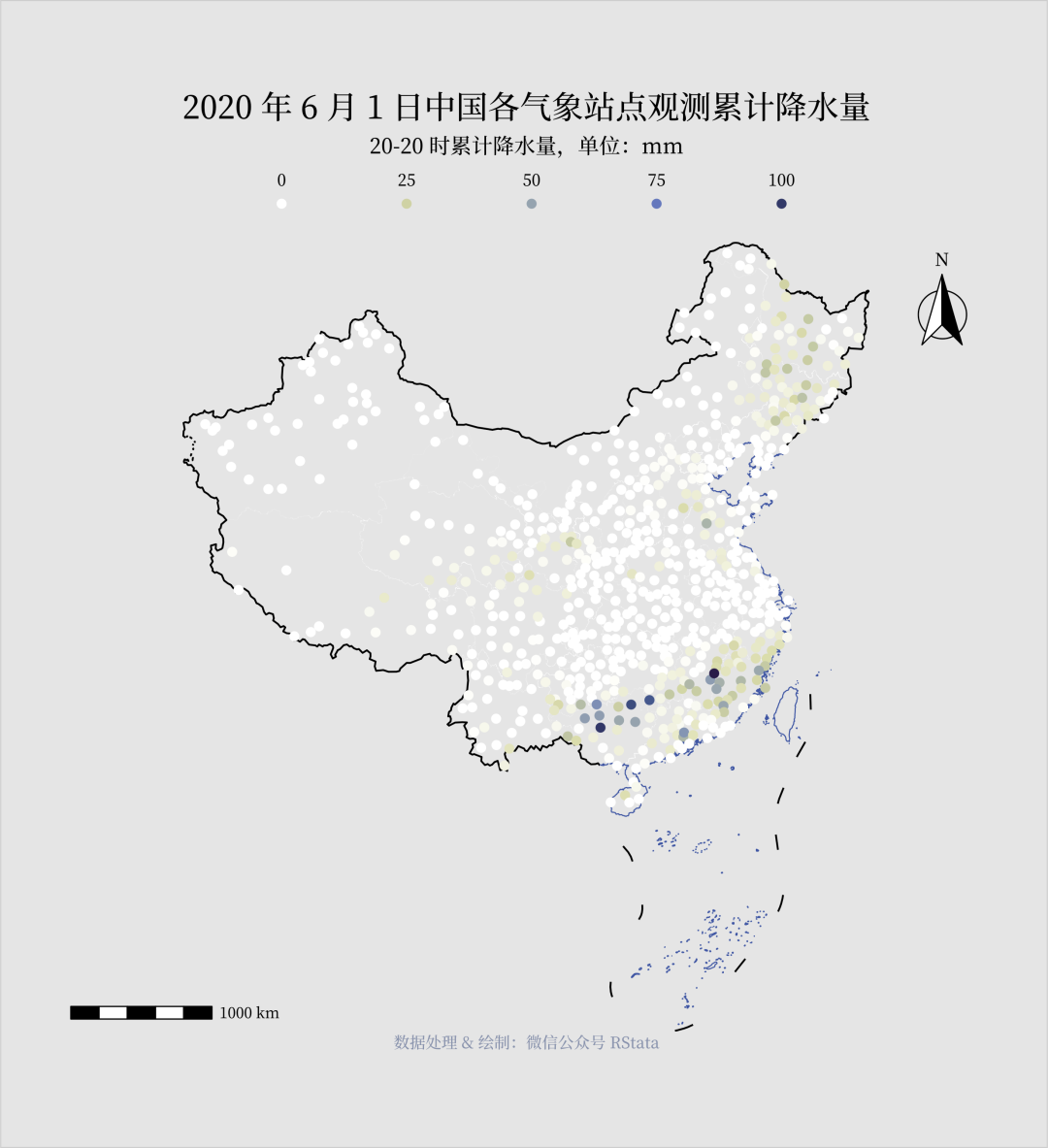
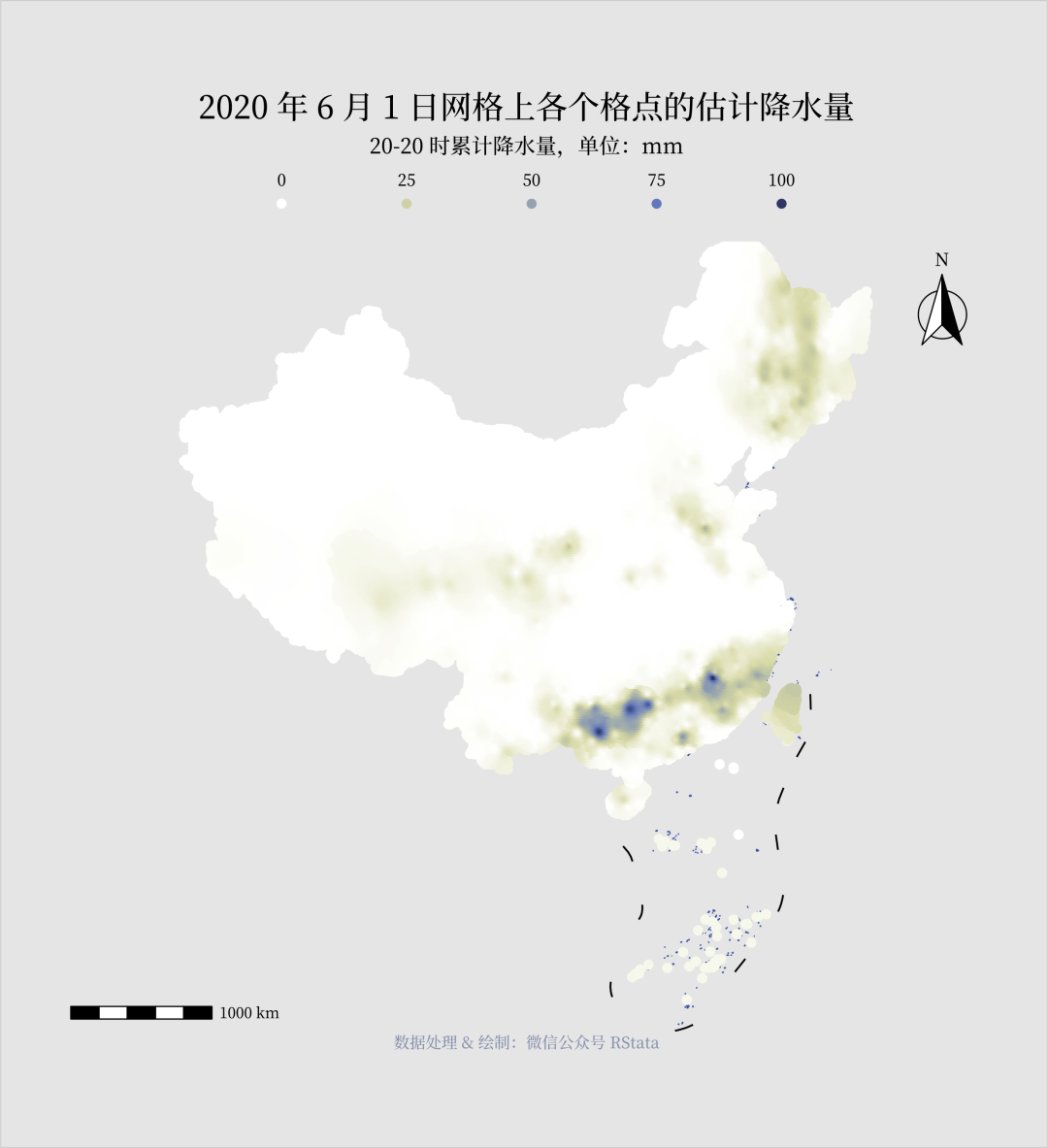
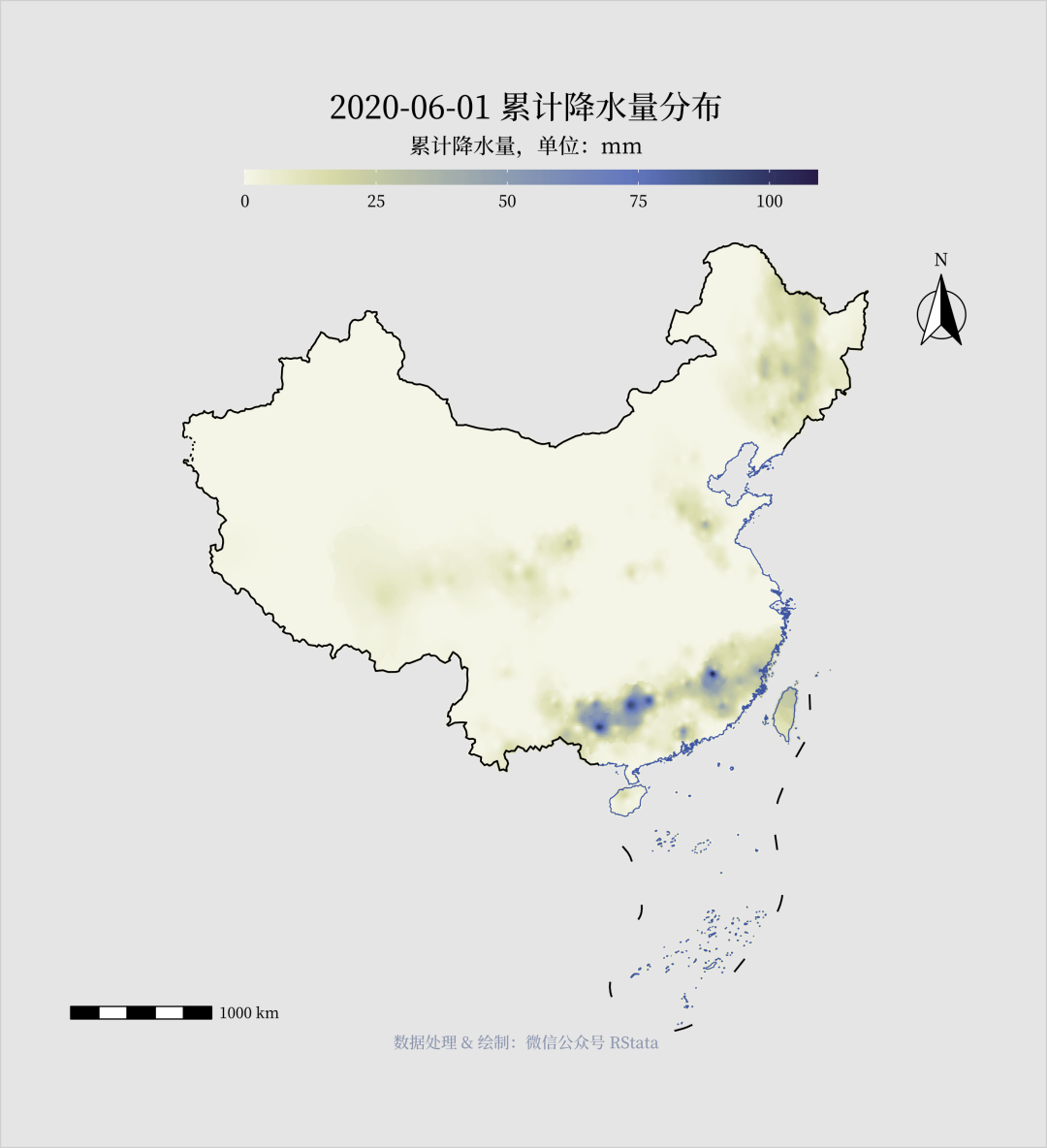
library(tidyverse)
library(showtext)
showtext_auto(enable = TRUE)
font_add("songti", regular = "song.otf")
cnfont <- "songti"
library(hrbrthemes)
theme_set(
theme_ipsum(base_family = cnfont) +
theme(axis.text.x = element_text(angle = 20, vjust = 0.4),
axis.text.y = element_text(hjust = 0.4),
axis.line.x = element_line(),
axis.line.y = element_line(),
panel.grid.minor = element_blank(),
axis.ticks.length = unit(1.5, "mm"),
axis.ticks.x = element_line(size = 0.2),
axis.ticks.y = element_line(size = 0.2),
panel.grid.major = element_line(linetype = 3, size = 0.5),
plot.background = element_rect(color = "white"))
)
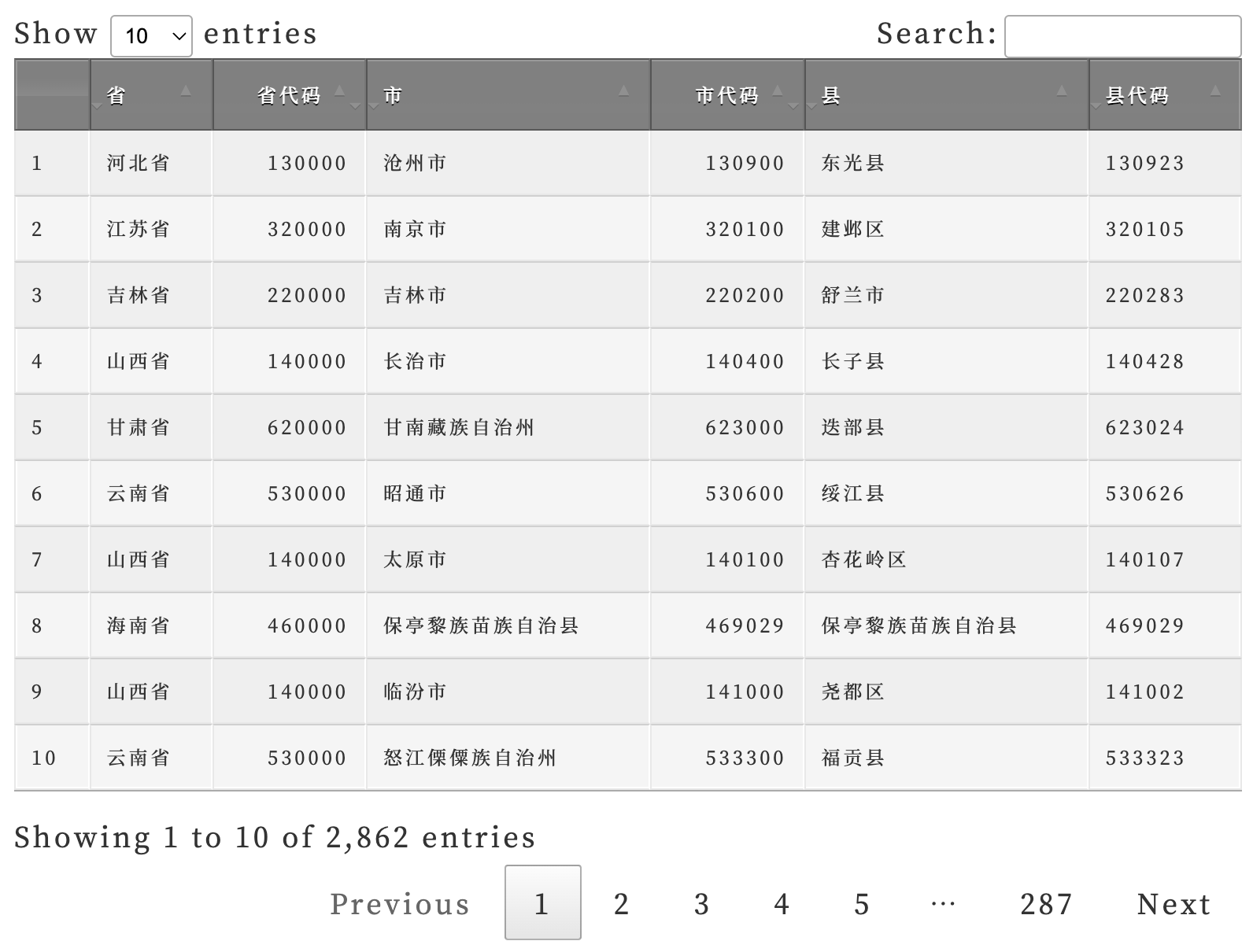
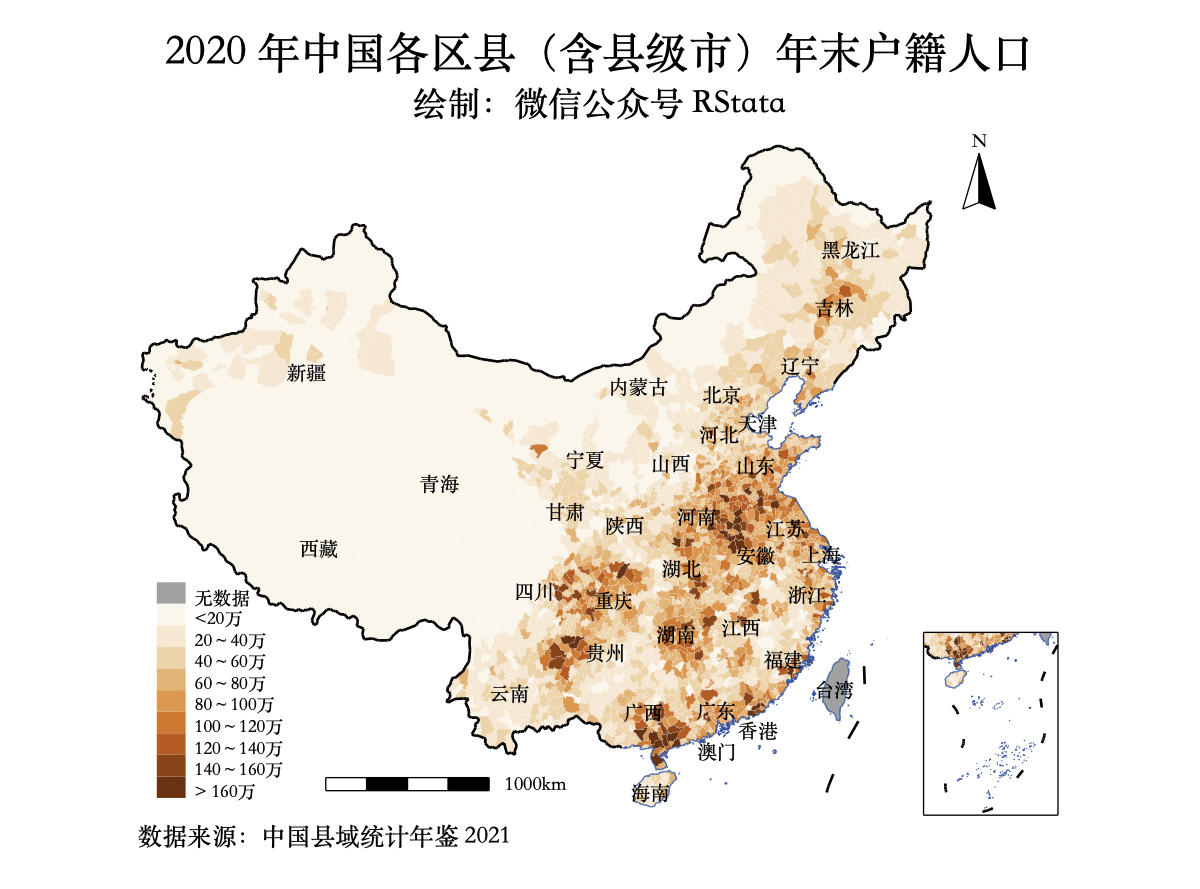
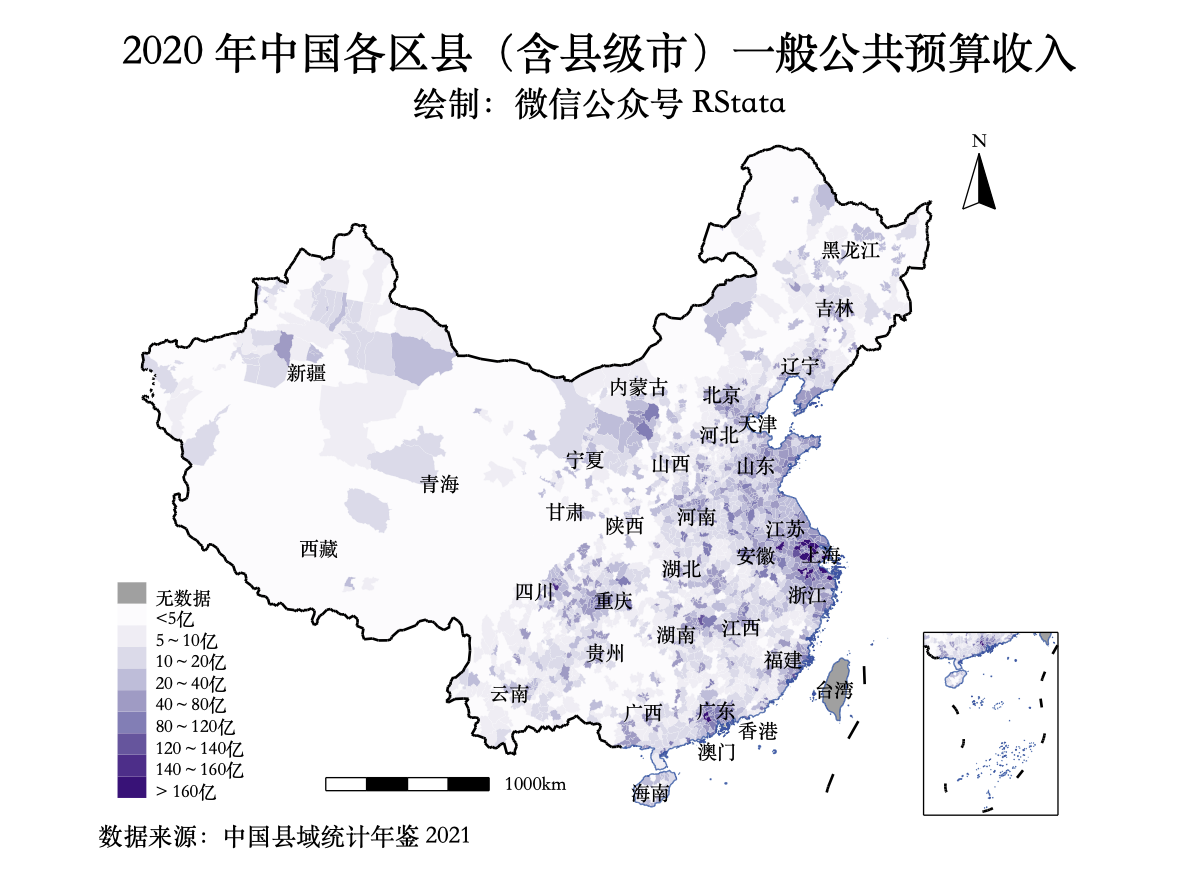
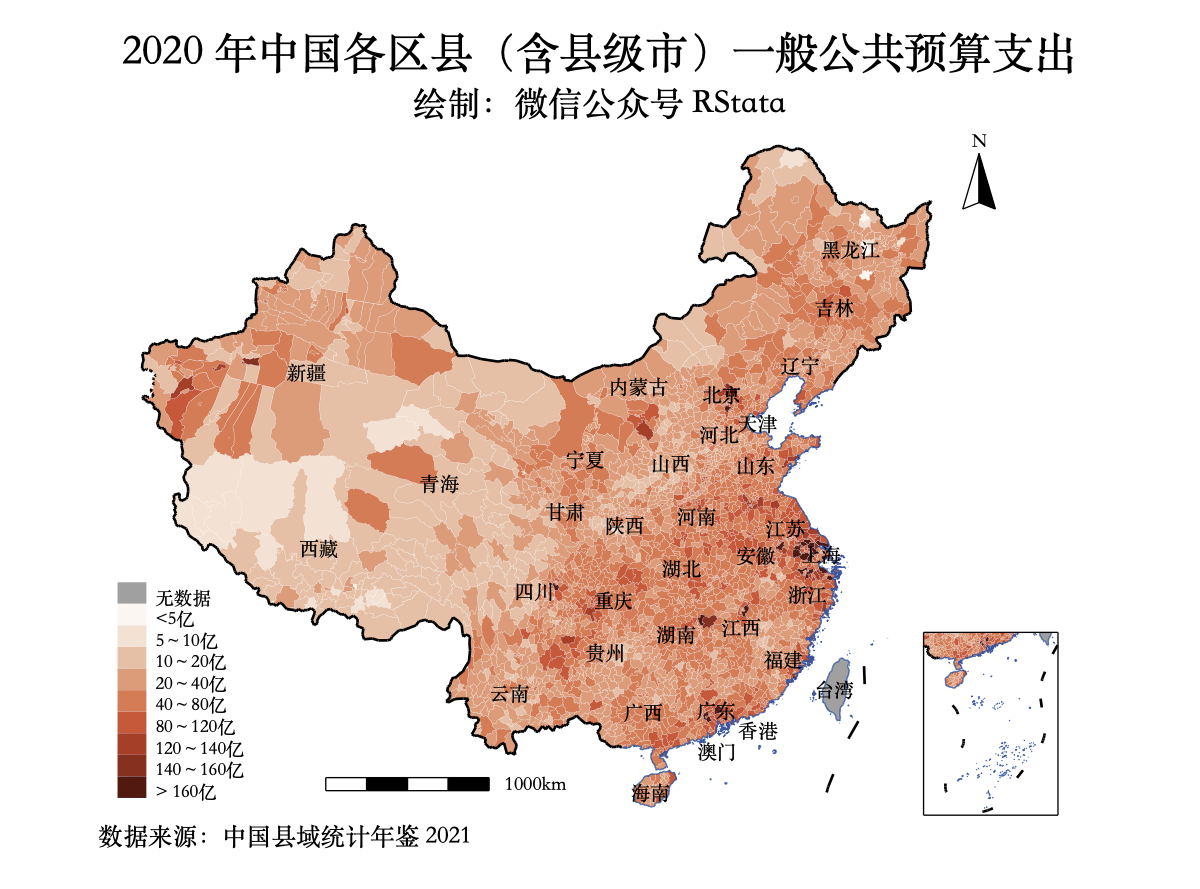
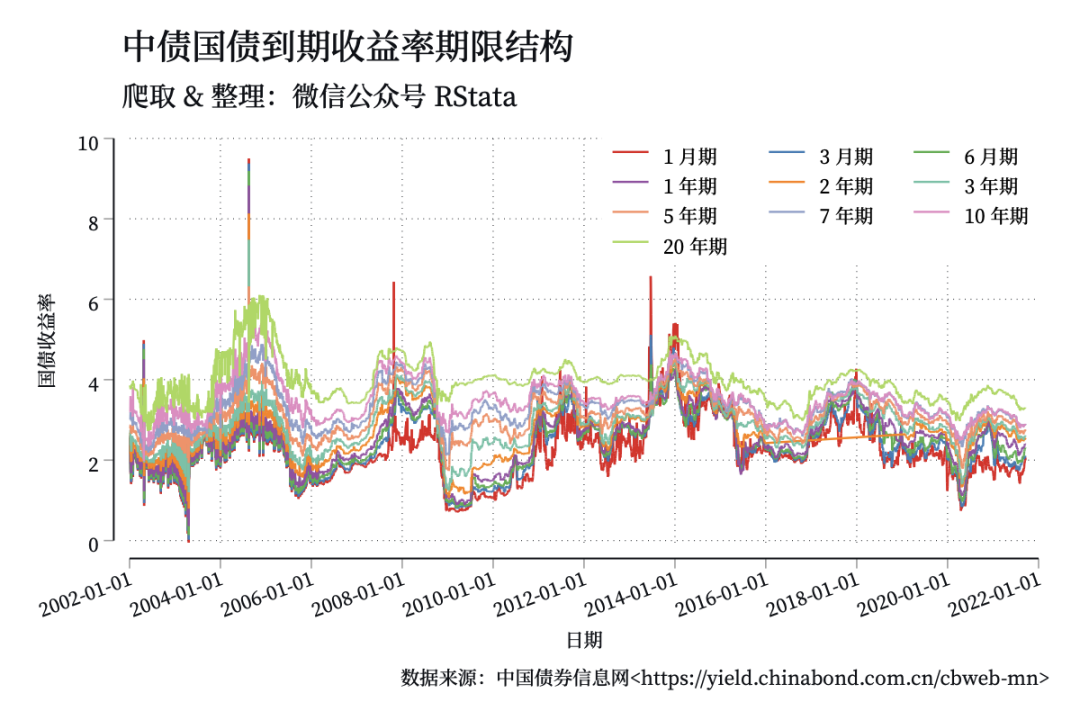
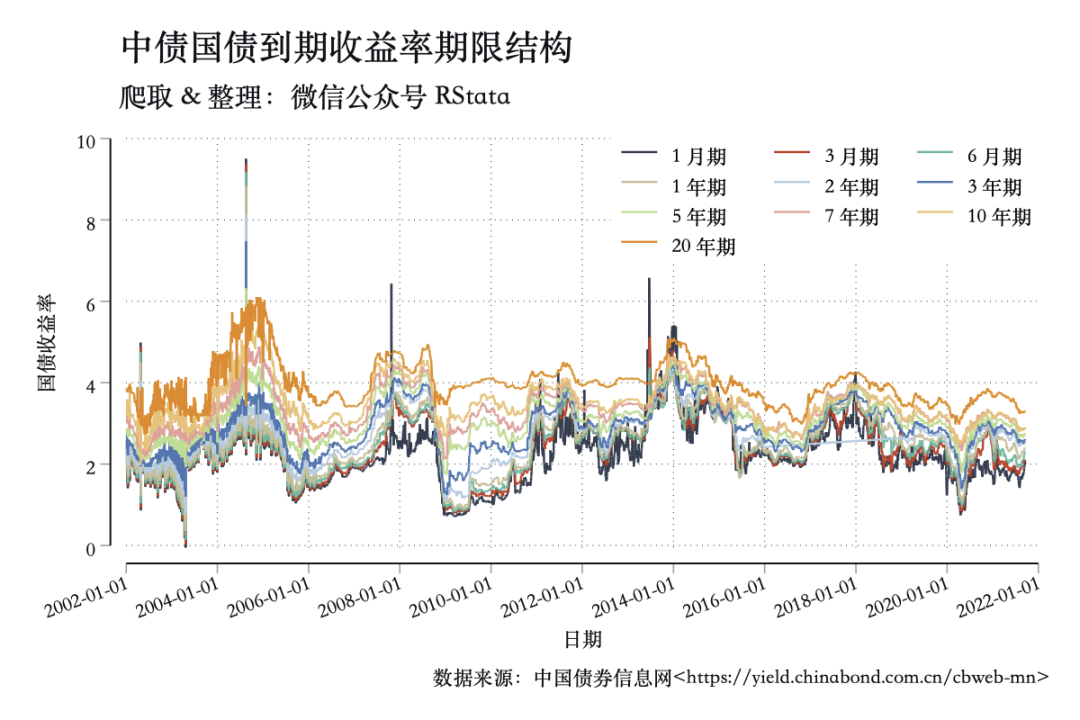
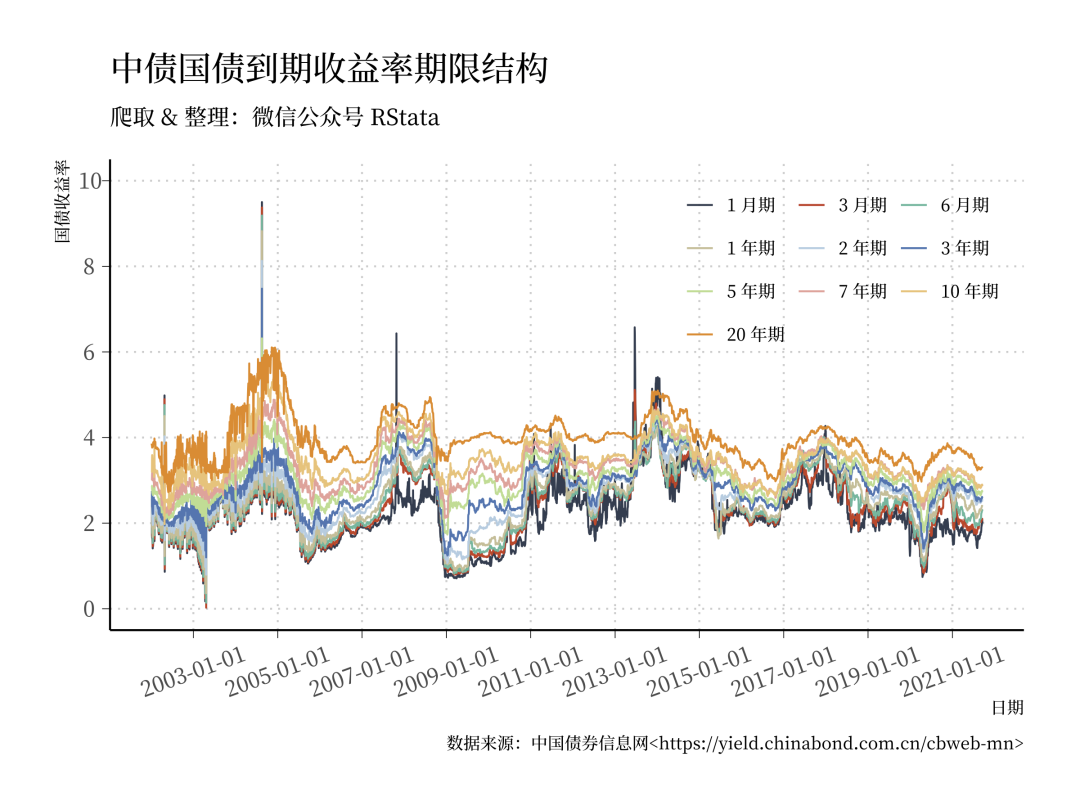
haven::read_dta("中债国债到期收益率数据(截止2021年9月20日).dta") -> df
df %>%
select(date, rate1m, rate3m, rate6m,
rate1y, rate2y, rate3y,
rate5y, rate7y, rate10y,
rate20y) %>%
gather(-date, key = "key", value = "value") %>%
mutate(key = factor(key,
levels = c("rate1m", "rate3m", "rate6m",
"rate1y", "rate2y", "rate3y",
"rate5y", "rate7y", "rate10y",
"rate20y"),
labels = c("1 月期", "3 月期", "6 月期",
"1 年期", "2 年期", "3 年期",
"5 年期", "7 年期", "10 年期",
"20 年期"))) %>%
ggplot(aes(x = date, y = value, color = key)) +
geom_line() +
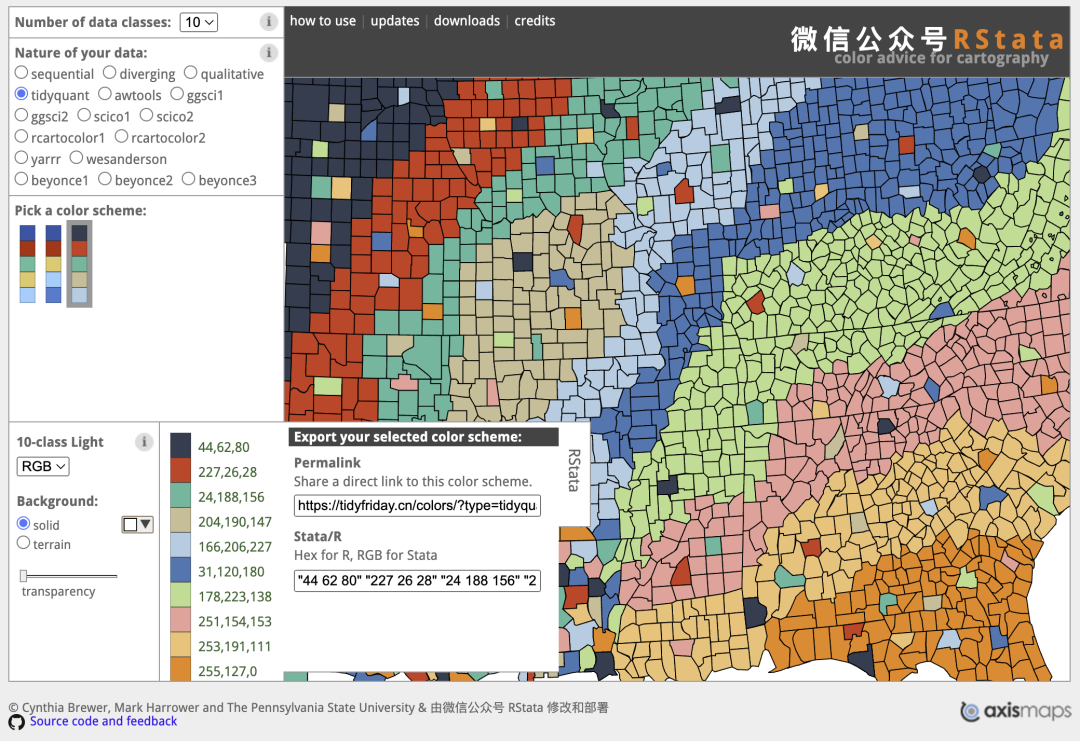
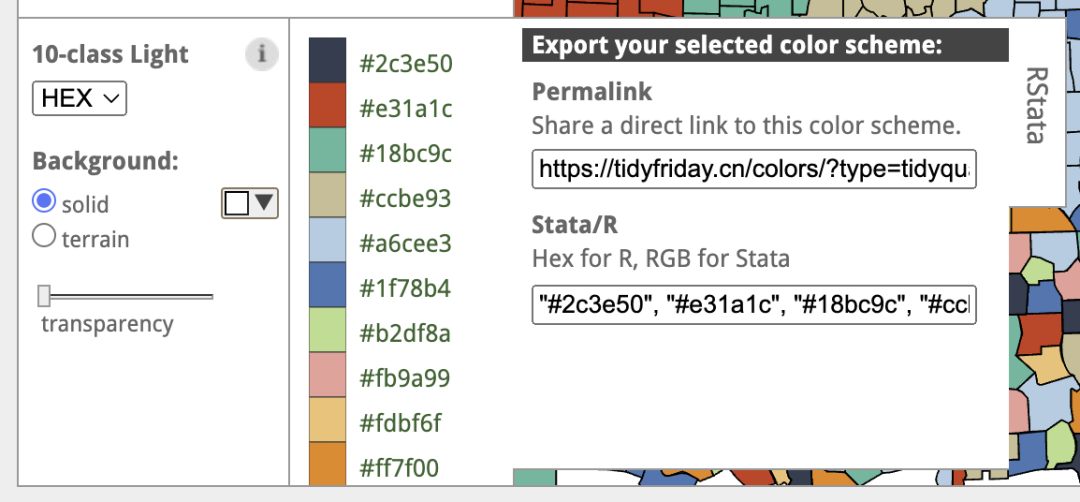
scale_color_manual(values = c("#2c3e50", "#e31a1c", "#18bc9c", "#ccbe93", "#a6cee3", "#1f78b4", "#b2df8a", "#fb9a99", "#fdbf6f", "#ff7f00")) +
theme(legend.position = c(0.8, 0.8)) +
guides(color = guide_legend(nrow = 4, byrow = T)) +
scale_x_date(labels = scales::date_format(),
breaks = scales::date_breaks(width = "2 years")) +
scale_y_continuous(breaks = seq(0, 10, by = 2), limits = c(0, 10)) +
labs(title = "中债国债到期收益率期限结构",
subtitle = "爬取 & 整理:微信公众号 RStata",
caption = "数据来源:中国债券信息网<https://yield.chinabond.com.cn/cbweb-mn>",
color = "", x = "日期", y = "国债收益率")
ggsave("中债国债到期收益率期限结构2.png", width = 10, height = 6, device = png)
|