在之前的课程「R 语言:如何整理 2022 年县域统计年鉴:caj 文件转 pdf、文本识别与数据清洗」中我们讲解了如何从 caj 文件中提取表格数据的方法,今天我们再来学习下如何根据区县名称匹配行政区划代码,另外在该过程中还可以检查区县名称的识别错误。最后我们再使用整理得到的数据绘制一幅区县地图。
首先我们使用上次课的代码处理“整理结果3.xlsx”:
# 处理 “整理结果3.xlsx” |
由于之前我分享的县域统计年鉴数据都是使用的 2020 年行政区划代码,所以这次我们也同样。
2020 年行政区划代码可以从地理矢量数据得到(为了方便绘制地图):
library(sf) |
首先匹配下看看能成功多少:
# tidylog 包的 join 族函数可以显示匹配效果: |
查看匹配失败的:
# 查看匹配失败的 |
可以看到很多是由于空格和杂乱字符导致的匹配失败,所以我们先去除:
df4 %>% |
可以看到这个时候匹配不成功的就不是很多了,下面我们需要结合百度和 countycode1.dta 来逐个检查修正:
DT::datatable(countycode1) |
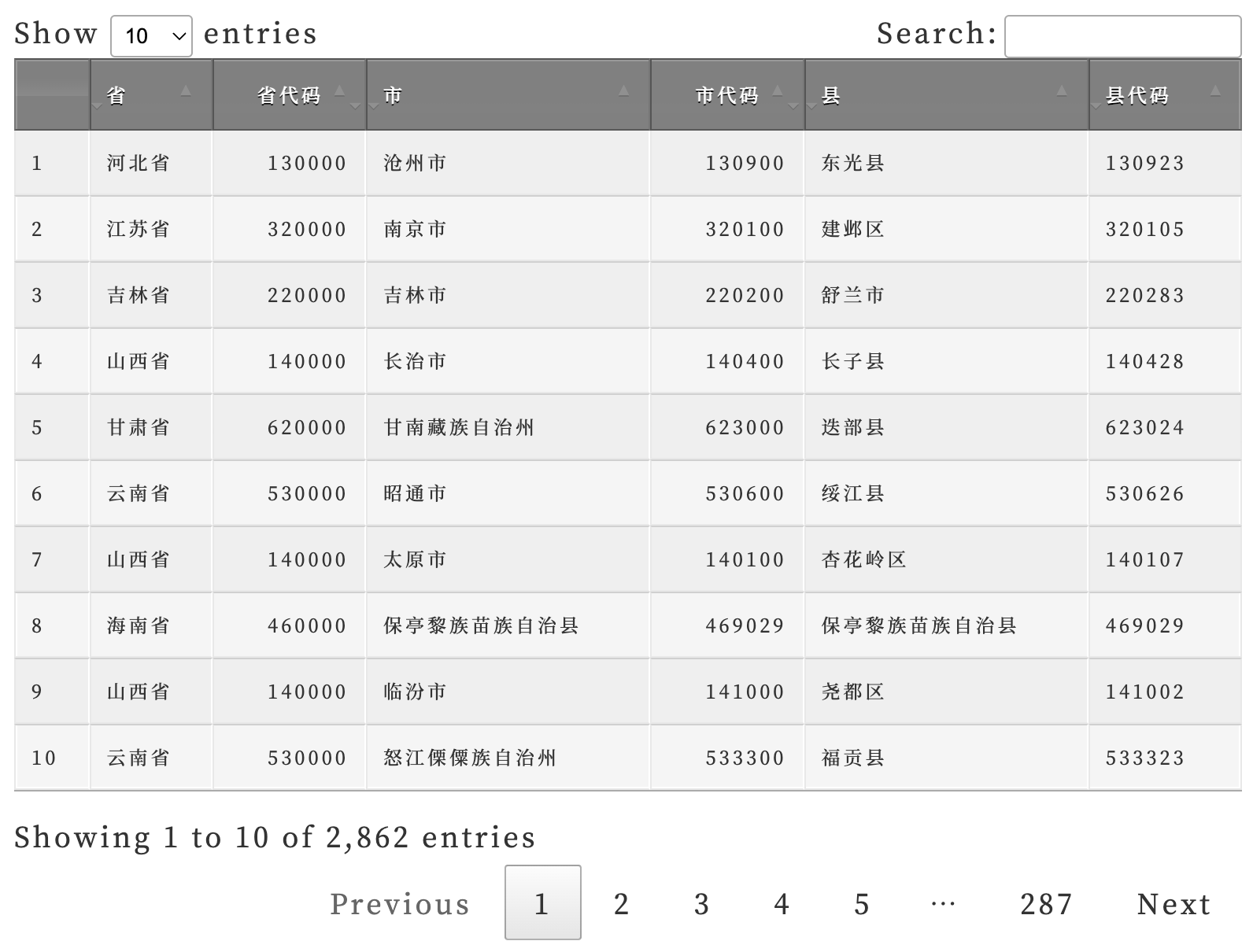
这里建议先保存成一个 xlsx 文件,然后在 Excel 里面进行更正:
df4 %>% |
这个时候就没有不匹配的了:
df4 %>% |
然后我们再对变量进行重命名(和之前年份的保持一致):
df5 %>% |
最后如果你想把该数据和之前年份的合并起来,只需要使用 bind_rows() 合并即可。
最后我们再使用该数据绘制一幅区县地图。这里使用的数据是我之前编辑过的一份 shp 数据。可以用于绘制带九段线小地图的中国地图。
library(ggspatial) |
以地区生产总值为例:
df6 %>% |
缺失值使用所在市、所在省的均值填补,实在无法填补的设定为 -1:
countymap %>% |
下面我们将绘制两种地图,一种是使用连续变量绘制,另一种是使用分类变量绘制,为此,我们对地区生产总值变量进行分组:
# v 的范围 |
countyline 变量还需要再处理下:
countyline %>% |
连续变量的绘制:
# 绘制连续变量 |

分类变量的绘制:
# 绘制分类变量 |
