前不久给大家分享过工企地理位置信息数据和海关地理位置信息数据:
- 工企地理位置:1998~2014 年工业企业数据库地理位置数据(含经纬度、所处省市区县、南北方属性以及距离秦岭淮河线的距离)
- 海关地理位置:2000~2016 年海关地理信息数据(含经纬度及其所处的省市区县)
今天我们分享一份工企与海关数据的匹配结果,借鉴相关文献,工企与海关的匹配可以分为下面 5 个步骤:
- 清洗工企数据库里面的企业名称、邮政编码和固定电话变量(等下要用这三个变量进行匹配);
- 清洗海关数据库里面的企业名称、邮编和电话变量;
- 在工企数据库里面生成一个 ID 变量用以在匹配过程中识别每个观测值,然后只保留企业名称、邮政编码和固定电话、年份、ID 几个变量(这样可以避免因为数据过大导致匹配过程过慢);
- 对海关数据库进行汇总(例如只需要每个公司每年的进出口额的话);
- 匹配海关和工企数据然后再根据 ID 变量把工企数据库的其它变量也合并进来。
关于这五个步骤的代码实现,可以学习我们之前推出的 Stata 课程:「如何匹配海关和工企数据?」:
如何匹配中国工业企业数据库和海关数据库?以 2013 年为例:https://rstata.duanshu.com/#/brief/course/5463b8d7afcb438ca1e537fa76c1a45d
这次分享的数据包含下面两种版本的:
- 先把海关数据汇总成每个公司的进出口额数据,然后和工企数据匹配的结果数据(下面称为汇总版本,其观测值是一个个的公司);
- 直接把海关数据和工企数据进行匹配(下面称为完整版本,其观测值是一条条的商品)。
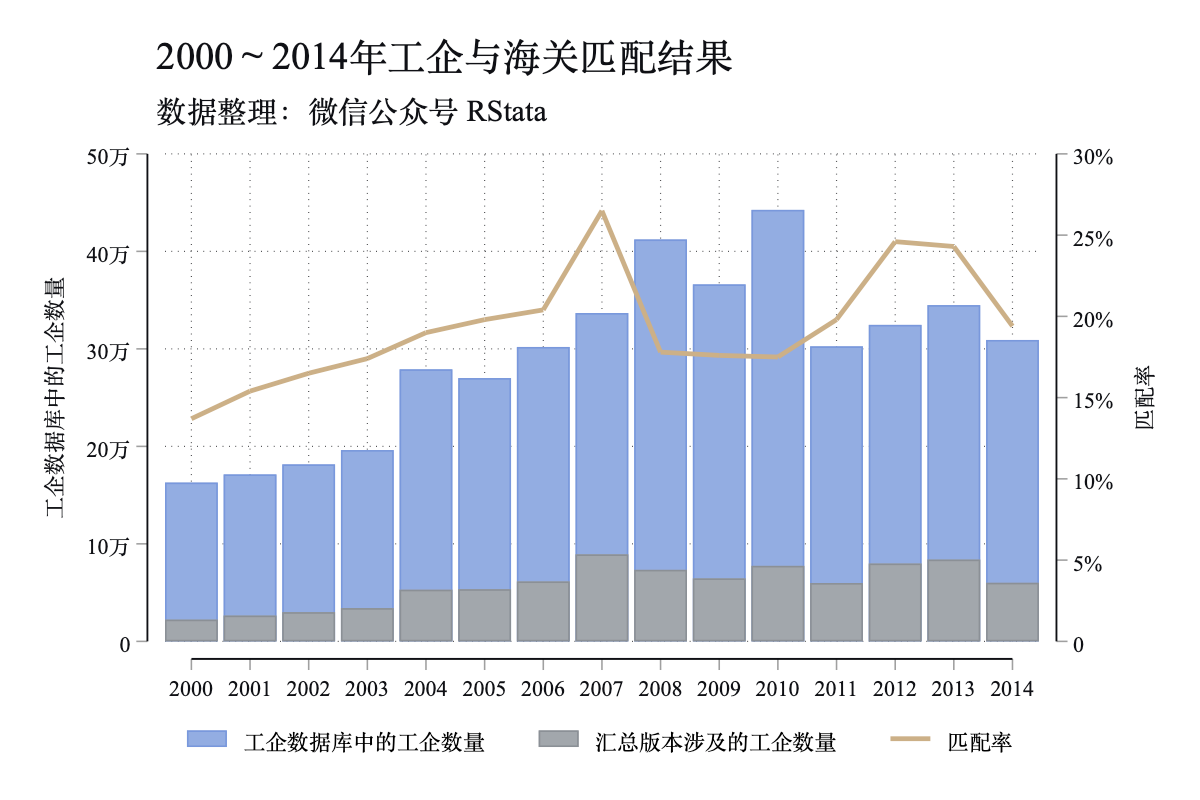
两个版本的结果数据使用的匹配方法是一样的,但是由于细微的差异,结果也有细微的差异,下表展示的是匹配效果。工企数据库中的工企数量 列展示的是匹配使用的工企数据库的每年样本数;汇总版本涉及的工企数量 列展示的是汇总版本匹配结果中涉及的工企数量,最后一列是匹配率(汇总版本涉及的工企数量 / 工企数据库中的工企数量):
| 年份 | 工企数据库中的工企数量 | 汇总版本涉及的工企数量 | 匹配率 |
|---|---|---|---|
| 2000 | 162872 | 22310 | 13.7% |
| 2001 | 171254 | 26446 | 15.4% |
| 2002 | 181542 | 29943 | 16.5% |
| 2003 | 196206 | 34096 | 17.4% |
| 2004 | 279011 | 52966 | 19.0% |
| 2005 | 270023 | 53475 | 19.8% |
| 2006 | 301930 | 61467 | 20.4% |
| 2007 | 336732 | 89237 | 26.5% |
| 2008 | 412212 | 73364 | 17.8% |
| 2009 | 366130 | 64562 | 17.6% |
| 2010 | 442539 | 77420 | 17.5% |
| 2011 | 302593 | 59789 | 19.8% |
| 2012 | 324604 | 79824 | 24.6% |
| 2013 | 344875 | 83893 | 24.3% |
| 2014 | 309138 | 60068 | 19.4% |
下图会更直观:
如果大家想自行匹配的话,可以使用文初提到的两个数据,然后参考课程匹配。
为了更好的确认匹配数据的可靠性,我们计算了每年平均各个公司的进口额和出口额,如下图所示:
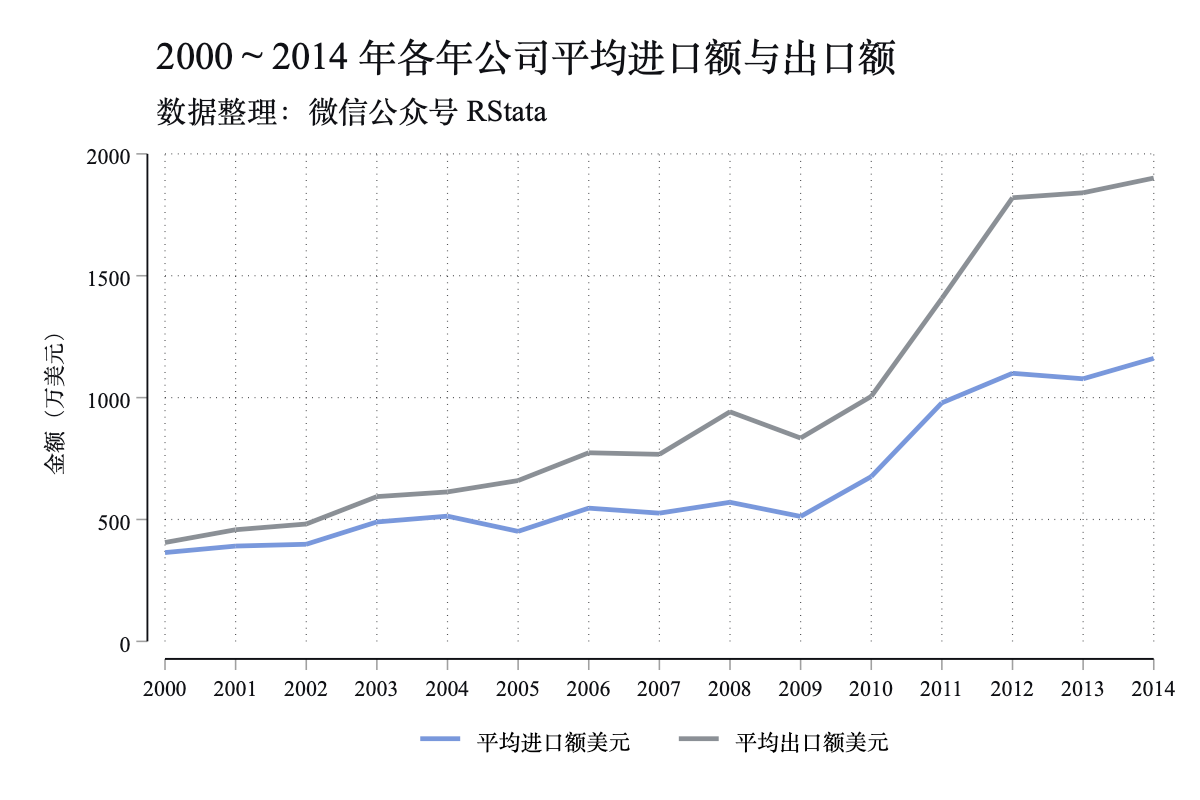
感觉连续性还不错!
另外这两份数据都非常大,已经拆分成了逐年的数据,可以直接使用 append 进行合并(Stata),数据格式是也是仅提供供 Stata 读取的 dta 格式。
关于汇总版如何合并成面板数据,可以参考这个课程:
如何仿照 Brandt 方法把工企数据匹配成面板?:https://rstata.duanshu.com/#/brief/course/a3e155a19934433ab90913f1547b8300
此次分享的数据还有一份:ID 对照表。提供这份数据的原因在于很多小伙伴的电脑内存不大,没法读取完整版本的结果(很多年份的完整版本有 20多 GB),另外也提供了一份分拆的海关数据(很多年份的完整版本有 20 多 GB,这样把每个年份的也都拆分成小文件更方便大家操作)。
尽管如此,还是担心大家的电脑无法读取这份大数据,所以我还提供了一份完整版的小文件分拆版(每个文件不到 2GB)。
下面再展示下部分的数据预览: