电脑里面收藏夹里面收藏了很多网页,但是经常懒得翻看,而且难以检索,所以整理下都放到这里。
工具
- Convert curl to R
- Library Genesis:下载电子书
- PDF Drive - Search and download PDF files for free.:下载电子书
- DataV.GeoAtlas地理小工具系列
- Word Cloud Generator

- How can I apply a watermark on every page of a PDF file?
- GitHub Proxy 代理加速
- Free Programming Books – GoalKicker.com
R 语言


- Manipulate SVG Plots with JavaScript in R Markdown
- ggpcp: Generalized parallel coordinate plots with ggpcp

- Removing empty polygon from sf object in R?
- Garrick Aden-Buie - Setting up a new MacBook Pro
- Garrick Aden-Buie - Sharing Your xaringan Slides
- Regression and Other Stories - Tidyverse Examples
- PieGlyph

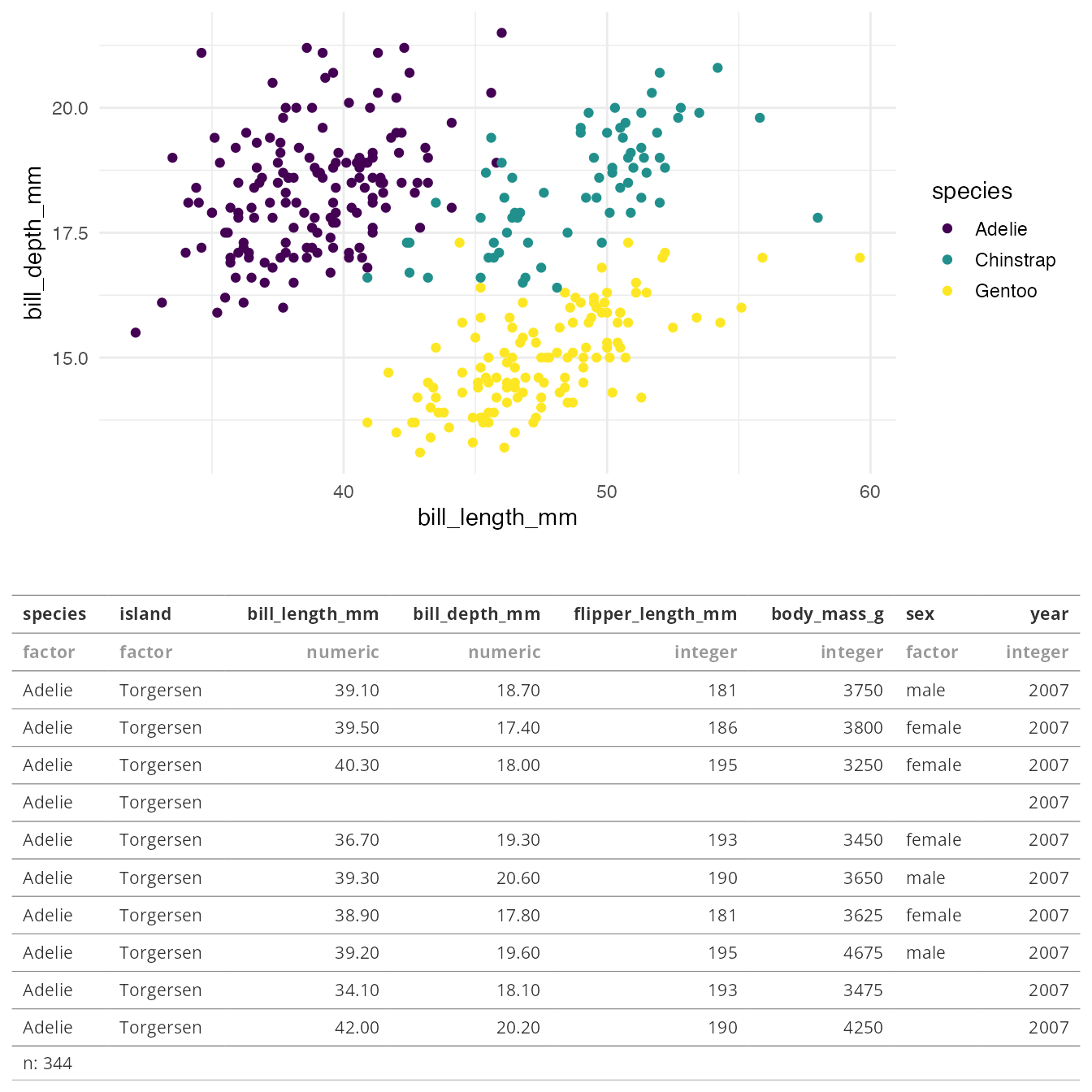
- Word Vectors with tidy data principles
- Use OpenAI text embeddings with #TidyTuesday horror movie descriptions | Julia Silge — 将 OpenAI 文本嵌入与#TidyTuesday恐怖电影描述结合使用 |朱莉娅·席尔格
- Using the Tesseract OCR engine in R
- How to create a clickable world cloud with wordcloud2 and Shiny
- Getting started with ‘ggmapinset’ • ggmapinset


chop_n(1:10, 5) |


- Applied longitudinal data analysis in brms and the tidyverse
- Exporting editable plots from R to Powerpoint: making ggplot2 purrr with officer
- Introduction to trelliscopejs
- Introduction to Econometrics with R
- long39ng/listviewerlite: View nested lists in R interactively using only HTML and CSS


- K-means clustering with tidy data principles
- Forecasting: Principles and Practice (3rd ed)
- The ‘ggcorset’ package

- Hands-On Machine Learning with R
- An Introduction to Bayesian Reasoning and Methods
- Causal Inference in Python: Applying Causal Inference in the Tech Industry 1st Edition
- R functions that shorten/filter stuff: less is more
- %dofuture% - a Better foreach() Parallelization Operator than %dopar%
Stata


- Asjad Naqvi 的 Medium 主页
- asjadnaqvi/stata-splinefit: A Stata package for spline interpolation between points

JavaScript
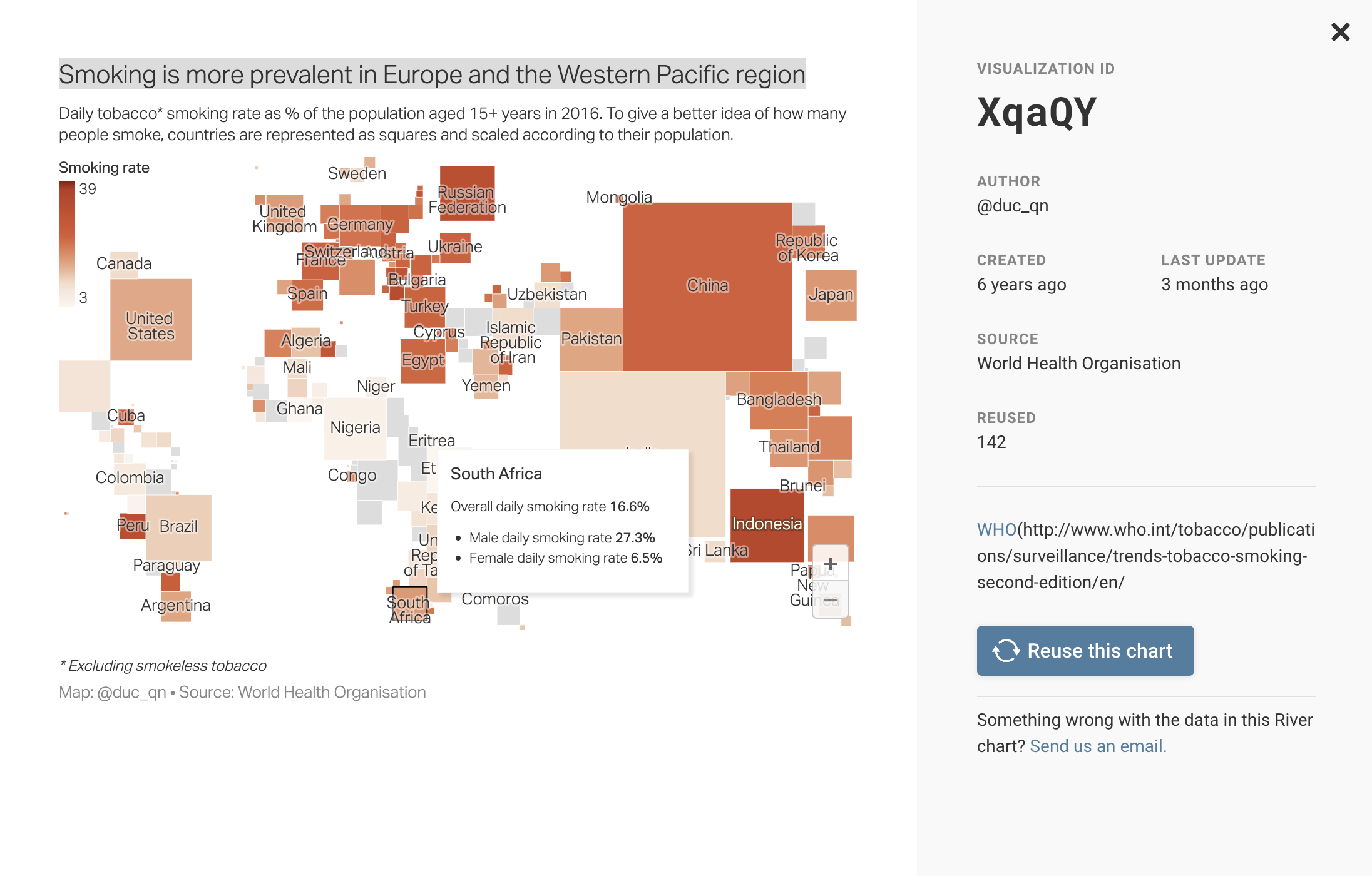

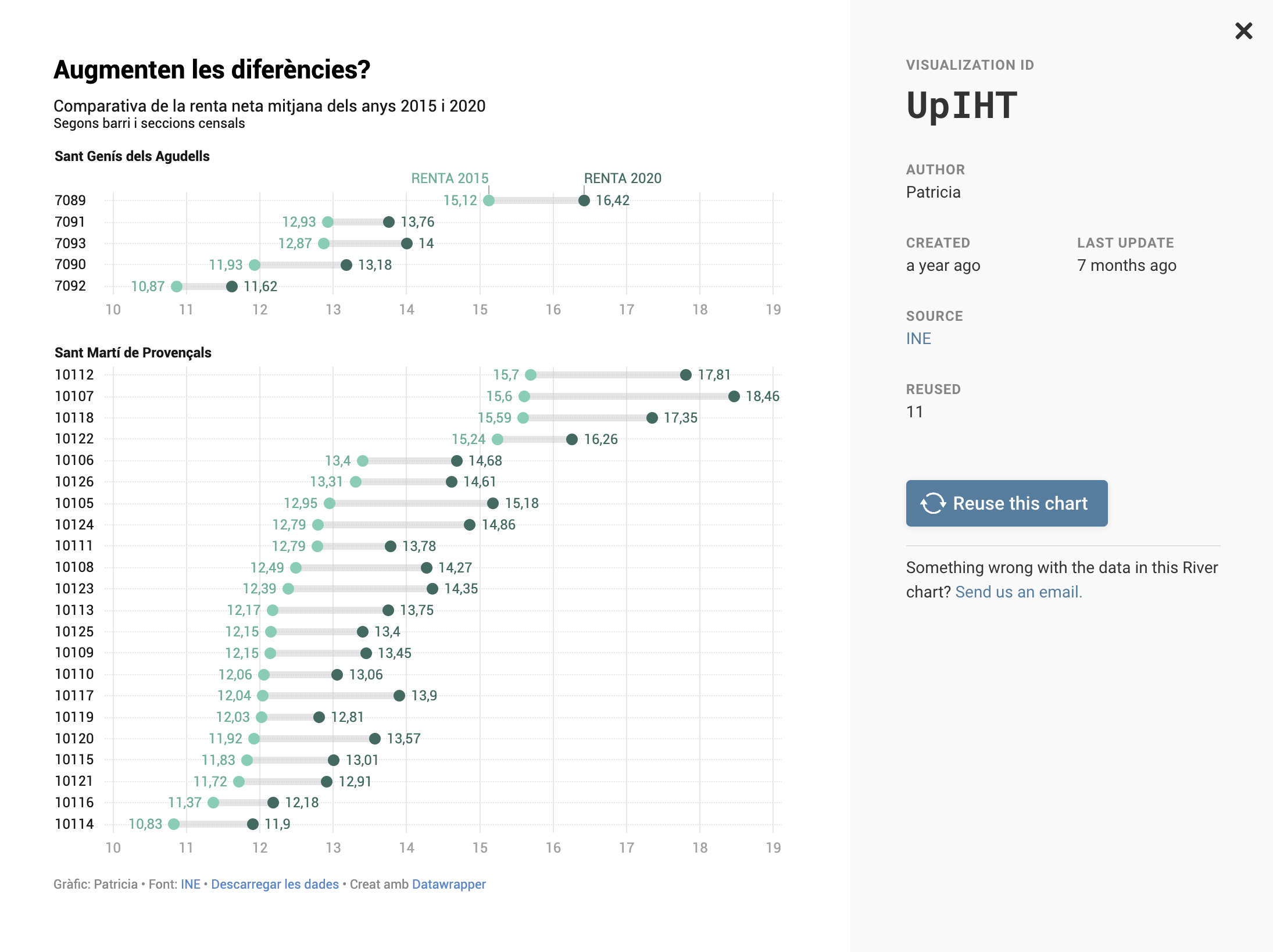

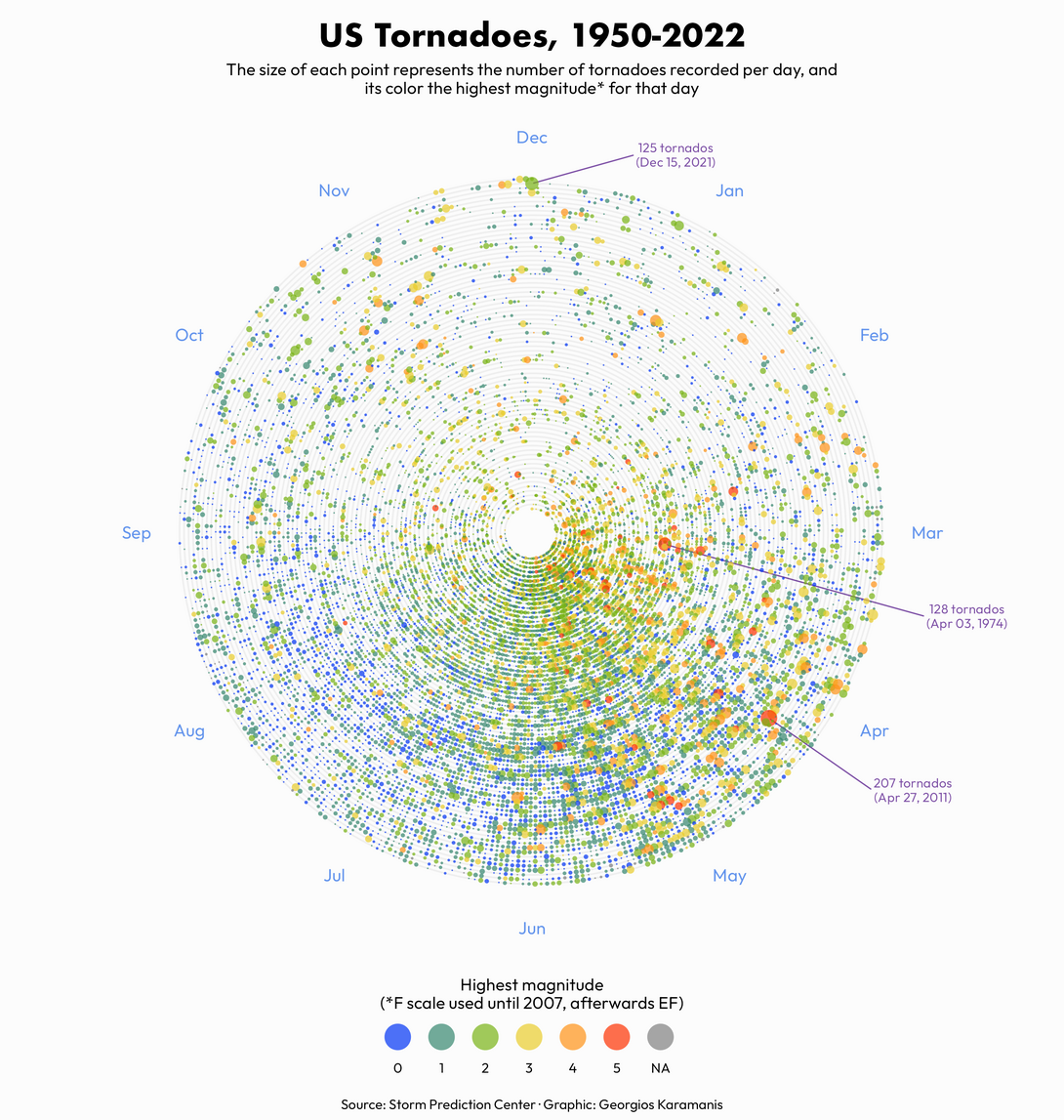

数据
- 中国区域经济统计年鉴
- US COVID-19 Daily Cases with Basemap - Data
- Kontur Population: Global Population Density for 400m H3 Hexagons - Humanitarian Data Exchange — Kontur人口:400m H3六边形的全球人口密度 - 人道主义数据交换
- 深证信数据服务平台 CNINFO Data Service
- 今日头条中文新闻(文本)分类数据集
- 基于站点观测的中国1km土壤湿度日尺度数据集(2000-2020)
- 哥伦比亚大学数据列表
- 中国交通年鉴
- Figshare - 为您所有的研究贡献力量 - 类别
- 数据库|中国瞪羚独角兽